任务调度器重构

为提升调度任务的规模,突破基于 etcd 存储状态进行调度的性能瓶颈,采用内存任务管理对调度器进行重构。
背景
任务调度器(Scheduler)是大规模业务系统的重要组成部分,其设计对系统的吞吐量、任务处理耗时、系统的稳定性等方面有着重要影响。
通常,Scheduler 需要考虑系统资源限制、任务优先级、任务抢占、调度公平性、调度延时等因素,需要针对不同业务系统作出权衡。
对于分布式任务调度系统来讲,还需要考虑高可用、调度数据一致性、崩溃恢复等问题。
我们的业务系统是图像识别系统,经历了如下发展阶段:
- 业务类型从最初的视频流人脸解析扩展到图片流人脸解析,扩展至基于视频流和图片流的人体、车辆解析,再扩展至脸人车绑定解析。
- 接入规模从单机单卡16路视频流到单机一百路图片流接入,再到单机8卡千路图片流接入,又到集群万路图片流接入。
- 业务场景从原始的实时视频流解析到离线视频流的解析,再到离线视频流切片解析。
业务类型和规模的扩张要求我们对现有的 Scheduler 进行重构。
原始任务调度器
我们调度的维度主要是 GPU 资源。在最初任务量少,类型单一的场景下,为了使系统更轻量,我们采用了基于 etcd 的调度策略。之所以采用 etcd,是因为我们使用 etcd 用作服务发现及分布式选主,早期的目标是在不引入额外组件的前提下完成调度。
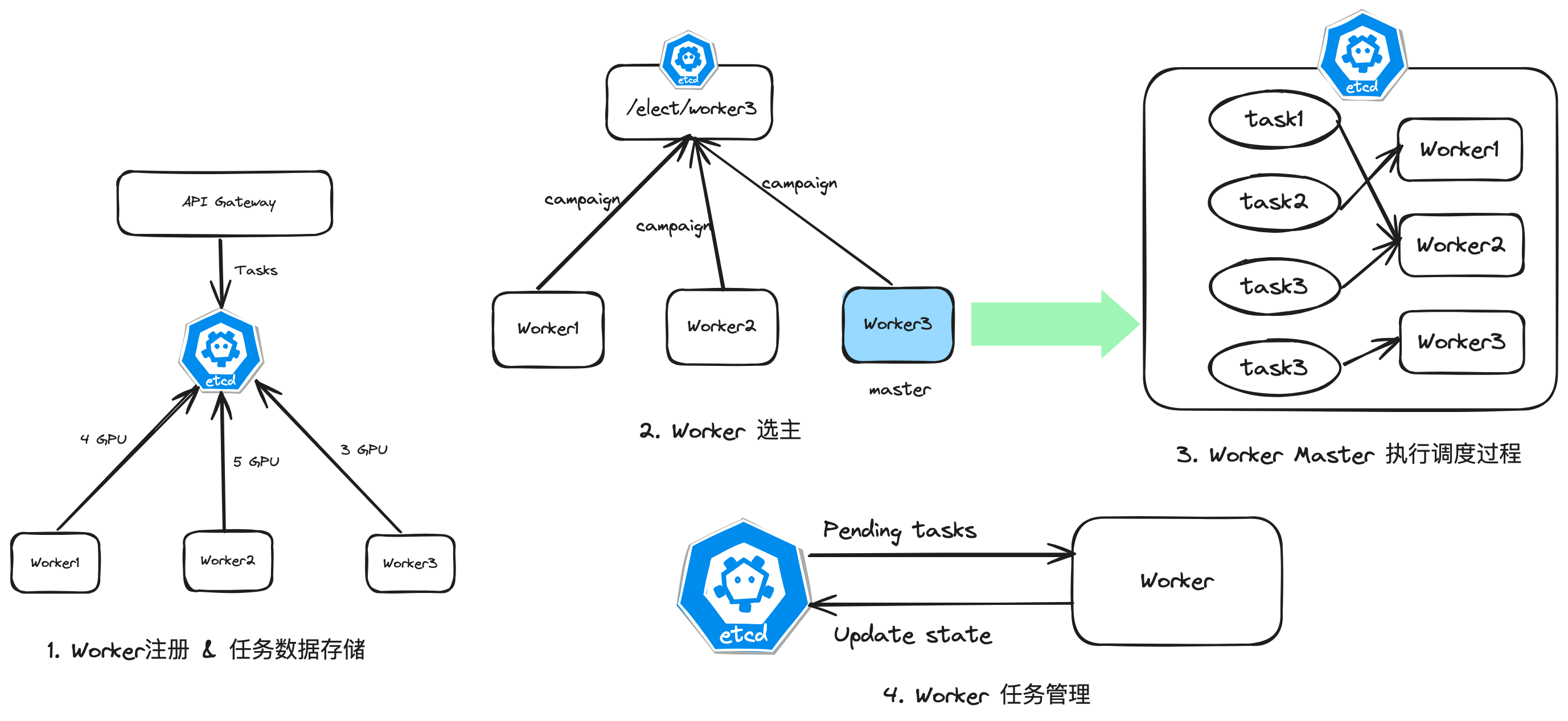
具体策略如下:
- 解析服务(Worker)在启动前,将其信息注册到 etcd 中,主要包含其所包含的GPU quota。
- Worker 启动一个异步进程,通过 etcd
election.Campaign()选择一个主 Worker 执行调度程序。 - 调度程序定期从 etcd 中拉取 Worker 列表与任务列表进行比较,结合节点状态、任务状态对任务进行资源分配、任务转移等调度操作。
- Worker 启动解析处理进程,定期从 etcd 中拉取分配给自身但未处理的任务进行处理,并对执行状态进行更新。
整个调度过程与 Kube-scheduler Pod 调度方式有一些类似之处,但存在以下差别:
- Worker 与任务的获取均采用拉取全量的方式,未采用 watch 机制。
- 没有单独的调度组件,调度程序与解析程序在一个进程内。
- 缺少缓存机制与 patch 更新机制,状态更新都是更新完整结构到etcd中。
随着接入路数规模扩大、解析类别增多,旧调度器的痛点突出,下面由重至轻列举一些:
- 频繁的状态更新导致 etcd 性能大幅恶化,出现频繁的连接超时,影响到服务发现。
- 参与 campaign 的节点过多时,当 etcd 性能不稳定时会偶发选主卡住的问题。
- 调度的延时过大。
- 未考虑网络中断的问题,在 etcd 不稳定的情况下,调度结果不一致(资源超配、误扣、同一任务被多个 worker 执行)的问题频现。
- 调度代码难以维护且扩展性差,新类型解析任务出现时,不得不将调度核心逻辑拷一份进行修改,维护多份类似的代码。
尽管期间我们通过很多方法缓解上述问题(如调整重试间隔,增加外部gc等),但随着路数进一步增加,系统性能明显变差,因此需要对任务调度架构进行重构。
重构目标
为解决原有 Scheduler 的痛点,我们提出如下的重构目标:
- 彻底缓解 etcd 压力,避免对选主、服务注册发现产生任何影响。
- 调度路数显著提升,支持百台服务器集群十万路图片流的调度。
- Scheduler 自身的扩展性要大幅增强,新增解析类型时可以在零学习成本下接入。
- Scheduler 高可用、崩溃恢复要得以保证。
- Scheduler 与 Worker 的数据一致性得以保证,调度需满足业务场景需求(优先级、抢占、排队、重试等)。
重构实现
我们主要采用以下几种方式对 Scheduler 进行重构:
- 任务元数据的存储从 etcd 转移到 postgresql 中以缓解 etcd 的压力。
- Worker 元数据依然保留在 etcd 中,但通过 watch 机制获取增量结果并缓存在内存中。
- 状态数据仅维护在内存中。
- Scheduler 改造成一个独立的微服务,通过 campaign 实现高可用。
核心流程
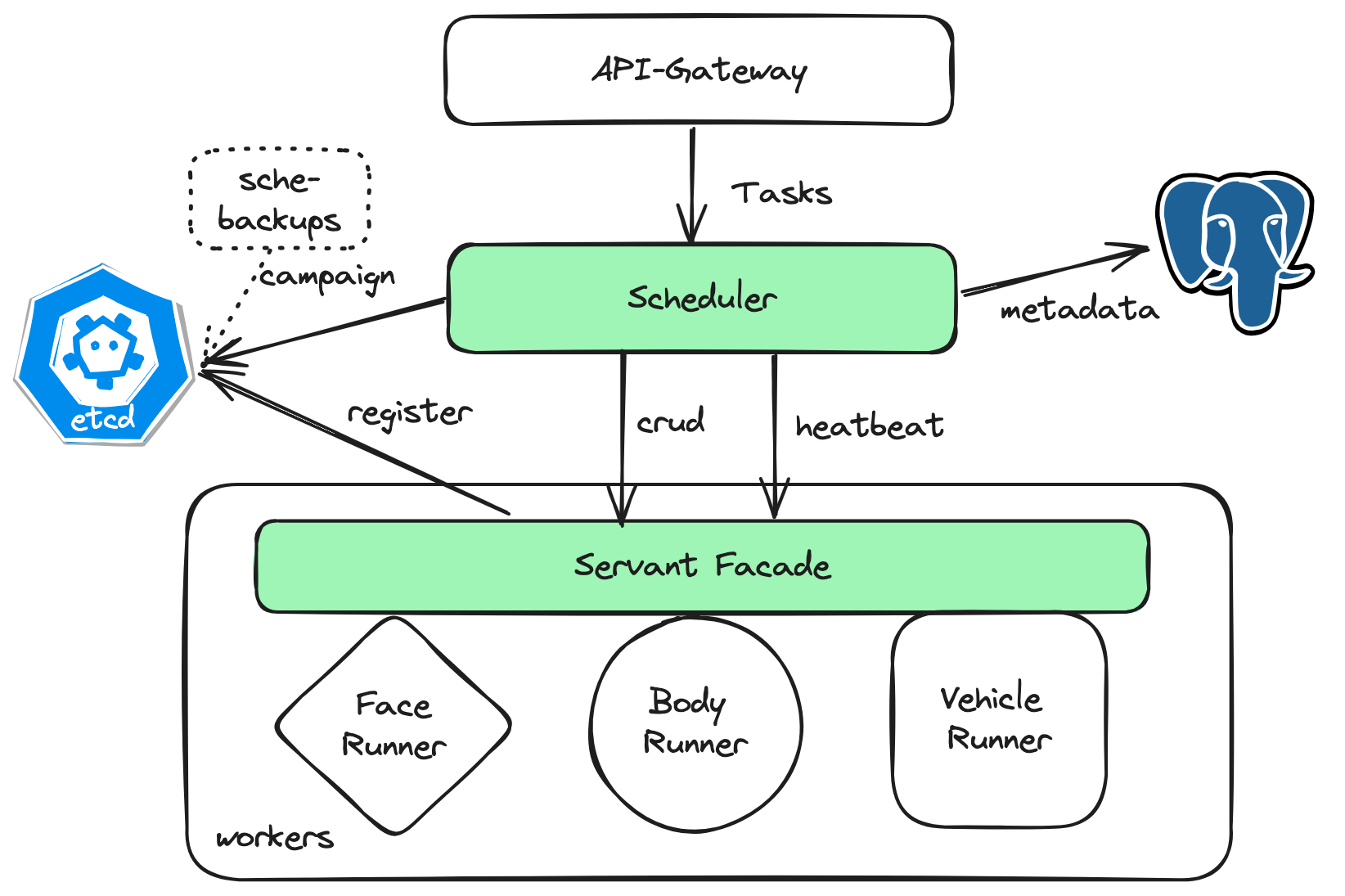
- Worker 向 etcd 注册 GPU 资源及可处理任务的类型。
- Scheduler 接收来自用户创建的任务,并将任务元数据进行落盘。
- Scheduler 通过任务队列的方式在内存管理状态,找出所有未分配的任务,并结合 Worker 剩余资源进行调度,更新状态机产生相应的调度 action(如 Create/Delete)。
- Scheduler 批量执行调度 action 以提升并发度。
- Scheduler 定期向所有 Worker 发起心跳请求,一方面确认节点是否正常工作,另一方面获取分配到 Worker 上的任务状态以更新状态机。
元数据与状态
任务的数据结构可以分为元数据与状态:
- 任务元数据:包括调度配置与任务处理配置,元数据需全部持久化。
- 调度配置:如占用资源、任务类型、任务优先级、restartPolicy 等。
- 任务处理配置:如视频流/图片流的 url、告警阈值、布控范围等。
- 任务状态:包括调度状态与处理状态,离线任务的状态需要持久化。
- 调度状态:包括任务被分配的 Worker 标识以及对应的资源标识(如 GPU index)。
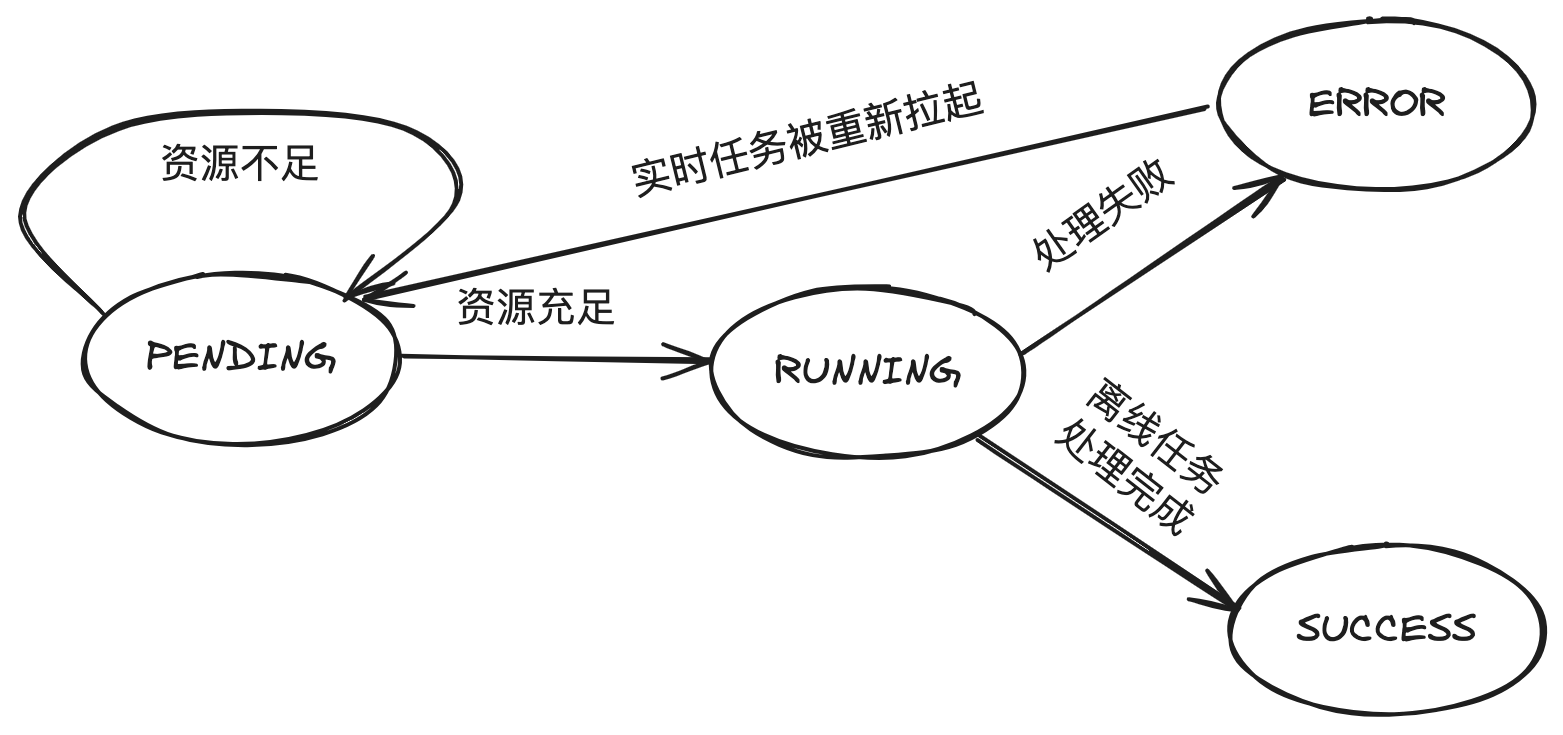
- 执行状态:任务当前的执行状态,包括 PENDING、RUNNING、SUCCESS、ERROR 等。
根据不同的任务执行状态,Scheduler 分别维护了 PENDING、RUNNING、ERROR 三个任务队列配合以下状态机实现任务调度与管理。
离线任务与实时任务
根据业务需要,实时任务和离线任务处理存在如下差异:
- 实时任务无法调整倍速,而离线任务可以调整倍速解析,倍速会映射到 GPU 资源占用上。
- 实时任务的优先级高于离线任务,实时任务可以抢占离线任务,离线任务无法抢占实时任务与离线任务。
- 实时任务支持暂停解析的功能,离线任务不支持暂停的功能,离线任务执行状态中 SUCCESS 与 ERROR 状态为终态,不会被重试拉起。
- 实时任务一旦失败后会被退避重新拉起。
类比 K8s workload,离线任务相当于 Job,实时任务相当于 restartPolicy=Always 的 Deployment。
Servant Facade
我们使用 Servant Facade 封装了复杂的任务管理流程,增强调度系统的可扩展性,便于接入新类型的任务。
每个 Worker 只需要传入 runnerFactory 到 Servant Facade 并注册到 GRPC Server 上即可实现对应的任务管理功能。
Servant Facade 主要封装了以下方法:
| |
Servant Facade 相当于 Scheduler 向 Worker 进程中注入的 Sidecar,承接来自 Scheduler 的全部流量并将相应的任务 hook 到 runner 中。这解耦了 Worker 任务管理和任务执行的逻辑,对 Worker 开发者屏蔽了复杂的任务管理流程。
故障转移
Scheduler 会通过 watch 的方式发现 Worker 节点的上下线,如果 Worker 因崩溃等原因使得注册到 etcd session 中断,Scheduler 会感知到 Worker 节点的下线,从而将分配到该节点的任务放入 ERROR 队列中等待重试。
如果 Worker 与 Scheduler 产生了网络分区,此时 etcd session 还在,调度节点无法通过服务发现感知到节点异常。这时 Scheduler 会通过连续几次心跳超时来将该 Worker 标记下线,该 Worker 上分配的任务放入 ERROR 队列里。 当某个节点连续多次分配任务失败时,逐步降低其调度权重,并在分配成功时恢复。
调度一致性
在分布式系统中,上述网络分区导致的故障转移会导致数据处理出现不一致的情况,最经典的是 At-Least-Once vs At-Most-Once。
- 当出现网络分区导致 Scheduler 与 Worker 断连时,Scheduler 会将任务从该 Worker 中转移到其他 Worker 中。由于之前的 Worker 还正常工作,因此在此期间会出现重复解析(At-Least-Once)的情况。
- 同样的网络分区场景下,如果 Worker 也感知到与 Scheduler 断连(比如定期检查是否收到心跳),并在断连后停止所有正在处理的任务,这会由于以下两种情况而造成至多解析一次(At-Most-Once):
- Worker 早于 Scheduler 感知到断连,因此在 Scheduler 重新调度任务前便终止了任务。
- 可用资源不够,导致部分任务无法被调度处理,这些任务会变成等待调度的状态。
由于我们项目很多是单 Worker 现场,因此我们选择了 At-Least-Once 策略。该策略使得 Worker 仅需要被 Scheduler 驱动,简化了系统的复杂度。
无论是上述哪个策略,当 Worker 网络恢复后,调度结果总能恢复到 Exactly-Once 的情况。但由于 Runner 的设计是高度自由的,数据不一致仍然无法完全避免。 因此 Scheduler 会起一个异步 matcher 线程定期地对 Scheduler 维护的 RUNNING Queue 与 Worker 中收集到的任务列表进行比较,以对以下不一致的问题进行校正:
- 某个任务在 Scheduler 中,但不在相应的 Worker 任务列表中。
- 某个任务不在 Scheduler 中,但在某个 Worker 任务列表中。
- 某个任务在多个 Worker 列表中出现。
高可用
Scheduler 本身无状态,采用冷备方式通过 election.Campaign 进行故障切换。
崩溃恢复
Scheduler 重启/切主时会根据 postgresql 中存储的元数据恢复任务,并通过发起一次心跳收集各任务的分配状态及运行时状态,结合二者构建出任务队列完成恢复。
为保证恢复数据的一致性,恢复过程中无法接受新的请求。
重构效果
- 调度路数大幅提升,调度延时不随调度路数增加而显著增长,mock 测试调度 QPS 能达到十万量级。
- etcd 后续未出现异常,解决计算节点(选主)过多时,依赖 etcd campaign 导致的选主卡住问题。