私有化交付平台——编排篇

编排就像搭积木,将零散的服务拼接成完整的系统。
服务编排
在大型微服务系统中,服务编排至关重要。服务编排泛指生成一组服务描述文件的方式,诸如docker-compose.yaml,K8S object file等都是通过编排一组文件来描述服务的部署规格。
为提升系统配置的灵活性和组件可复用性,编排过程通常会变为使用一组系统配置渲染服务模板的方式,如helm chart。这样开发者只需将一组服务规格模版给到用户,用户便可以提供一组配置来实现所需的系统部署行为。
由于编排的过程会产生系统中所有服务的描述文件,因此在一个多版本、依赖关系复杂的系统中,编排还需要具备依赖解析等能力以获取相应的服务模板的版本。
包管理器
微服务架构使组件发版变得更轻量、更敏捷,发版的频率大幅提升。具体表现为发布的服务数目变多、每个服务的版本激增。为了在众多的服务及海量的版本中挑选出满足系统功能需求、服务依赖约束、API兼容性的版本,包管理器应运而生。无论是语言类包管理器(如npm、pip、go module)还是应用类包管理器(如apt、helm),核心的功能便是提供规范的版本管理并屏蔽掉依赖解析、版本选择等复杂的流程。
版本管理
本平台采用通用的semantic version 2.0.0(semver)来作为组件包版本的规范。semver提供了如下规则以透过修改相应的版本号向大家说明做了哪些修改。
semver的版本定义基本形式为:MAJOR.MINOR.PATCH,其中
MAJOR为主版本号,当你做了不兼容的 API修改时,递增MAJOR。MINOR为次版本号,当你新增向下兼容的功能时,递增MINOR。PATCH为修订号,当你做了向下兼容的问题修正时,递增PATCH。
更完整的semver形式为:MAJOR.MINOR.PATCH-PRE+META
PRE为预发布号,当某个版本正式发布前,会通过预发布进行测试或给一小批用户进行试用体验,一般定义为alpha,beta这种表示当前功能成熟度或测试进行的阶段。具有PRE的版本为prerelease,否则为release。META为元信息,仅用作版本的标识信息,一般定义为发布日期等。
版本管理会更多关注版本的排序,通过版本排序找到最新发布的版本、最新稳定版本、某个MAJOR版本下的最新稳定版本等。
semver定义的排序规则总结如下:
- MAJOR、MINOR、PATCH按序进行比较,一旦某位比较出了大小,版本大小便据此确定。如果都一致,则根据PRE比较大小。
- 主版本号相同时,prerelease版本小于release版本,两个prerelease版本的顺序按字PRE字母序排序。
- META不影响排序。
依赖管理
包管理器主要职责在于选出能让用户选择的包正常运行的所有依赖包的版本,其最核心功能是依赖解析。
依赖声明
首先,包开发者需要在包的描述文件中声明一组依赖及版本约束,我们看一个npm package.json依赖定义方式:
| |
通常情况下,某个组件声明依赖是为了使用其部分能力,比如调用其API辅助完成自身的功能。但在交付的视角下,将组装关系视作依赖关系可以提升交付效率,实现整个产品的一键安装。
所谓组装关系,指的是使用一个虚拟包关联一系列的组件包,将关联的组件包声明为依赖关系,包管理器可以按依赖解析的规则选择这些组件的版本。通常虚拟包并不包含任何真实负载(不是一个真正的组件),它只用来关联系统所需的包,其中的代表是archlinux的meta package。这一方式不仅使得安装复杂应用变得更加简便,也使得包的扩展性、复用性大幅提升。
我们从业务的角度定义了三类包:
- 组件:可以真正部署的包,如redis,粒度最小。
- 模块:组装一部分具备某一功能组件的包,如storage模块组装了redis与mysql组件,粒度适中。
- 产品:一个完整的业务产品包,组装若干模块、组件,粒度最大。
通过引入虚拟包的概念, 我们可以对组件/模块/产品三个维度进行复用与部署,大幅提升交付效率。
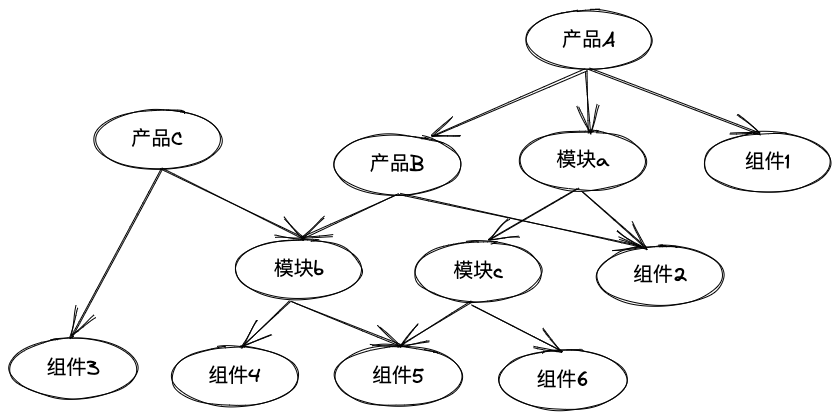
版本约束
描述文件需要包含依赖包名及对其的版本约束。版本约束主要用作兼容性保证,以^5.4.3为例,它表示依赖的版本号必须满足>=5.4.3 && <6.0.0,不能选择5.0.0,因为可能缺少它所依赖的某些功能;也不能选择6.0.0,因为它所依赖的API可能存在breaking change,与依赖方的调用的api不兼容。
与semver不同,版本约束并没有一个标准,我们采用了与helm一致的规范。此规范与npm等包管理器版本约束不一致的点在于对prerelease的选择上,即版本约束的形式为release时,不会匹配到任何prerelease。这种形式并未完全按照版本排序规则匹配版本,而是结合顺序与稳定性语义进行选择。其将稳定版的选择区分开,更适合生产环境下的版本选择,例如>1.0.0会匹配到1.0.3,但无法匹配到1.0.3-beta。
版本选择
通常情况下,依赖版本约束通常为一个范围,而不是一个固定的版本,这样做的好处是便于升级更新。这也意味着在包管理器仓库里,可能存在多个版本满足约束条件,那么包管理器该选择哪个版本呢?
依赖的版本选择也是一个见仁见智的决策。比如稳定性优先的GO MVS会选择满足所有版本约束的最小版本,其宗旨为既然大家都不需要用最新版本,那就没有必要使用最新的版本。而与之相对的是,大多数阵营会选择满足约束的最新版本,这样做的好处是选择最新的版本可以修复很多已知的问题,也可能会添加一些很cool的功能。他们唯一需要关心的是避免选择一个不兼容的版本,他们会选择相信所有开发者都遵循semver。约束大多定义为^X.Y.Z,这通常表明我测试时依赖版本选择的是X.Y.Z,但只要依赖的的主版本号不变(没有breaking change)就可以放心选择最新的版本。
我们采用的是第二个方案,但我们突出了对prerelease的考量,按照semver的规范,我们不希望在交付过程中选择不稳定的版本,而一些研发/测试场景又希望选择这些版本,这正是我们选择Masterminds/constraints约束规则的原因。
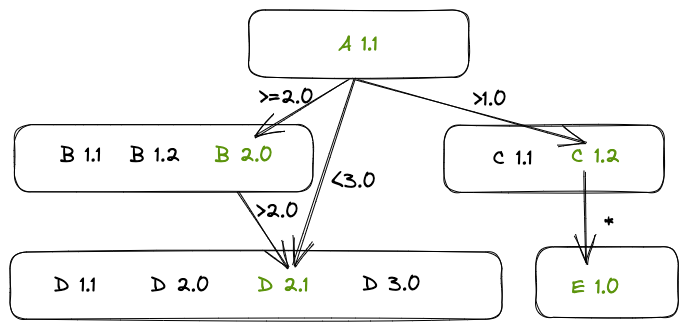
当然这种自动的版本选择有时不能满足我们的需求,比如组件C满足条件的最大版本为1.2,但这个版本由于加入了一些功能后,导致了性能所有下降,需要回退到1.1。我们当然可以将约束收紧为~1.1,但是如果C在后来的某个版本修复的问题,我们还需要手动地把约束改回去。更常见的方式是提供人工更新某个组件版本的方式,就像go get C@1.1、npm update C@1.1一样。
版本锁定
尽管大家希望尽量使用最新的版本,但更需要关注的点在于版本选择的确定性,尤其是对于交付平台,保证交付产品的确定性是第一要义。
所谓确定性,指的是某个版本的包,多次安装/部署的状态是一致的。在软件开发的早期时代,最流行的说法便是:"在我的机器上可以正常运行",当然这与软件的可移植性相关,但是如果两个运行环境中部署的包不一致,其行为大概率不合预期,而这个问题在微服务架构下会被放大。
举个例子,比如某个被依赖的组件发了新的版本或者某个版本被修改后覆盖掉,那么按照最新版本选择策略部署依赖该组件的产品时,这个组件就会相较于之前部署的组件有所差别。这时我们会说:"同样的产品版本,之前部署就没问题,现在部署就有问题了"。这正是不确定性带来的问题,这个问题对于运维人员是一场灾难,因为他们会在"找不同"的流程上痛苦挣扎。
为了保证部署的确定性,我们需要如下两个规则:
- 项目一旦部署后,之后所有部署的组件版本不应发生变化。
- 每个组件版本的内容不应发生变化。
这就意味着版本选择仅发生在首次构建中,一旦产品确认后,依赖的版本不应发生变化。我们需要通过版本锁定来保证这件事,通常的做法是加一个lock文件,将首次构建选择的版本及内容hash记录下来,之后的每次部署只使用lock里的版本并校验版本是否发生了变化。
像npm、go module等包管理器都存在lock文件(package-lock.json、go.mod/go.sum),确保每次部署都可以选择一致的版本,并且这个版本的hash未发生变化。
模板渲染
模板渲染是一种提供灵活性数据更新的重要手段。模版渲染通常用在网页构建中,将展示的内容框架构建成模版,并使用实时的数据渲染模板,形成动态变化的网页。
在系统部署中,业务配置决定了部署形态的多样性,这些配置包括资源相关的配置(副本数、最大使用内存容量)和功能相关配置(是否开启聚档功能,索引类型是内存索引还是磁盘索引)。为提升部署的灵活性,通常将应用的规格文件作为模版,而将系统配置作为渲染模版的数据。
模版引擎
模版引擎的种类繁多,每个模版语言都有各自适用的场景,也有相应的短板场景。支持合适的模板语言,是我们提升研发体验的关键。
模板引擎主要分为两大阵营:
- 文本型模版:直接以文本形式展示出规格文件的结构并注入模板变量,模版渲染更像是完形填空,此派别代表为jinja,go template。这类模板编写声明式文件时结构很直观,但在书写诸如判断、循环、计算等逻辑时格外复杂。
- 程序型模版:此类模版语言通常类似于编程语言,将规格文件进行结构化改造,以写代码的形式处理渲染过程,此派别可以使用任意的脚本语言(如Bazel Starlark),模版引擎相当于对应语言的运行器。此类模版可以很容易处理复杂的计算逻辑,但无法以直观的方式展示出规格文件的结构。
在本平台出现之前,我司编排工具大多使用python脚本生成,这推动了我们选择starlark模版引擎,以降低研发人员切换编排系统的成本。此外,为兼容helm chart,我们也支持了go template模版引擎。

配置管理
对应服务级交付平台,配置管理是决定交付效率最重要的因素。在一个大型应用系统中,配置管理主要面对如下挑战:
- 配置过多:大型系统可以包含上百个服务,每个服务又可能包含若干业务配置,导致交付人员面对近千个配置。
- 配置联动:由于系统中服务交互关系复杂,更改某一服务配置的同时要求更改其他服务的配置,这种联动关系要求配置变更按照某种规则同时发生,如果只更改一处而未更改其他的地方,可能存在无法预期的行为。
- 配置传递:服务A依赖服务B,并且希望控制服务B的部署行为时,配置需要从依赖方传递到被依赖方。比如应用根据自身一致性要求决定其依赖的kafka选择相关的复制策略。
- 配置依赖:服务A依赖服务B,并且希望获取B的相关信息时,配置需要从被依赖方反向传递到依赖方。比如某个应用依赖了mysql,并且希望获得mysql的endpoints。
在交付平台的配置系统中,一个由二八定律衍生的矛盾是:大量的配置让使用者无从下手 vs 过少的配置无法配置完整的功能。因此我们在精简配置的同时,需要保留对那些使用频率很少的配置变更的能力,即便修改这些配置很复杂。就好比变长编码会给低频符号较长的码字,但不会遗漏任何一个可能出现的符号编码。
隐藏配置过多的问题
针对配置过多的问题,我们首要任务是筛选出系统中高频变化的配置,这些配置通常会随着私有化环境的不同而变化,这类配置通常为:
- 限制系统整体资源的配置,如cpuLimit等。
- 控制系统功能的配置,如enableNotification等。
- 控制系统扩展性、迁移等运维配置,如replica等。
对于开发配置、调试配置、低频业务配置要尽量避免直接出现在交付系统使用者面前,这些配置一般会以高级选项的方式隐藏在某处,只有当系统破天荒地需要调整他们时,才会把他们翻到台面上。
支持配置联动
在Helm中,从父chart向子chart传值是很常见的,但是对于复杂系统来讲,helm的传值方式并不适用。因为配置通常具有联动性,比如某个系统中应用A的副本数必须与B的副本数完全一致,而其他的系统中不存在这样的限制。这就意味着在该系统中,修改A的副本数的同时也要修改B的副本数。这种限制给交付人员增加了额外的心理负担的同时,也引入了很强的易错隐患。配置联动性在大型系统中会被无限放大,设想一下,在一个100个微服务的系统中,如果只有固定的五种交付模式,那么只向用户暴露一个五选一的enum,而系统中服务的配置完全交给联动性,那么我们的交付流程会是多么的简洁!
另一方面,对于配置使用方而言,整个系统通常是一个黑盒。用户并不关心散落在各个服务上的配置,他们只关心系统暴露出来的配置,这就意味着交付系统需要隐藏配置在服务间传递的细节。交付平台在配置下发时,可以按照一定的规则进行加工并传递到相关的服务上。
总体来说,配置联动将灵活运用配置加工与传递,并为用户呈现出简洁的配置管理。
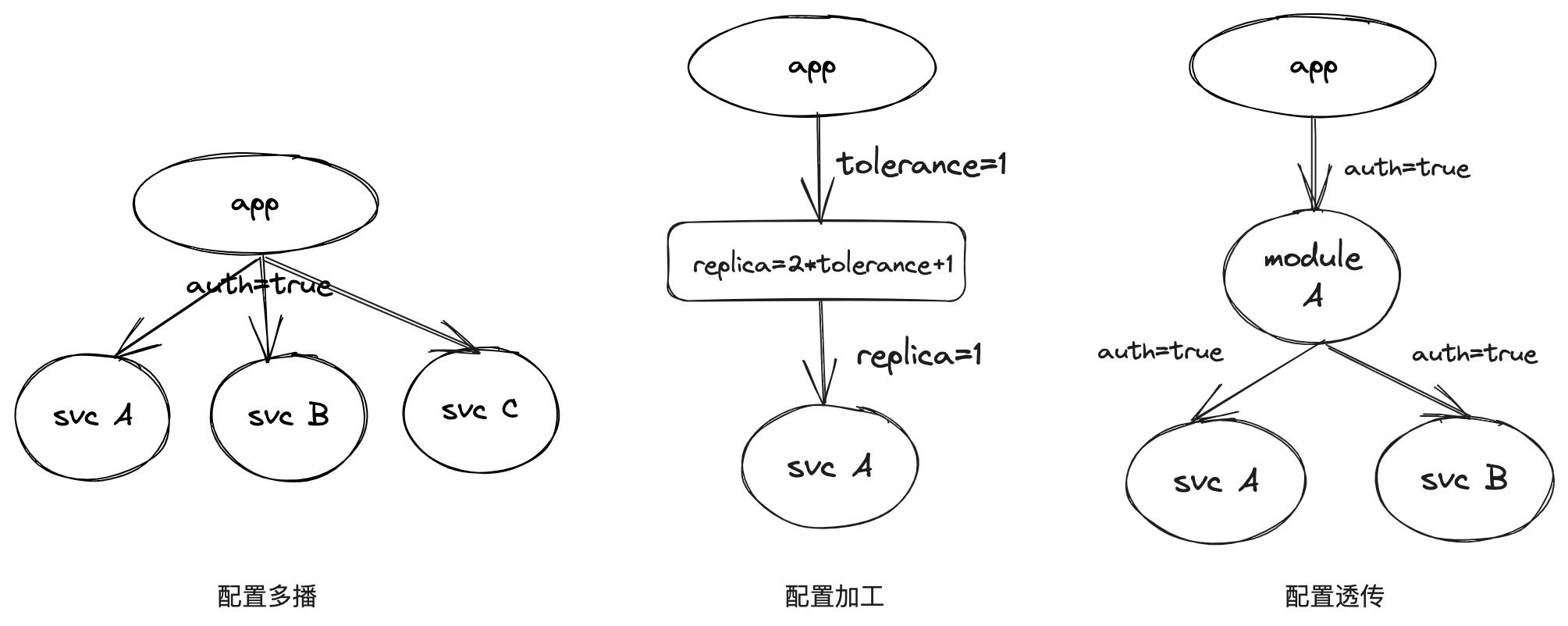
配置双向传递
配置传递包含两个方向,除了上述提及的由父组件向子组件的配置传递以外,还应对从子组件向父组件的配置依赖予以支持。我们称前者自顶向下的传递为正向配置传递,后者自底向上的传递为反向配置传递。
反向配置传递也是一个很常见的需求,比如对接第三方应用时,他们需要调用某一系统的api,而这个系统需要将系统的入口地址告知给第三方应用。这时,通常由gateway入口服务将自身的endpoint通过反向传递的方式暴露给系统。通常情况下,被依赖方都需要将自己的endpoint以反向配置传递的方式暴露给依赖方,只是借助域名管理系统,这种方式会显得无足轻重。但对于那些希望获取依赖组件运行时配置的场景,反向配置传递是最简单的解决方案。
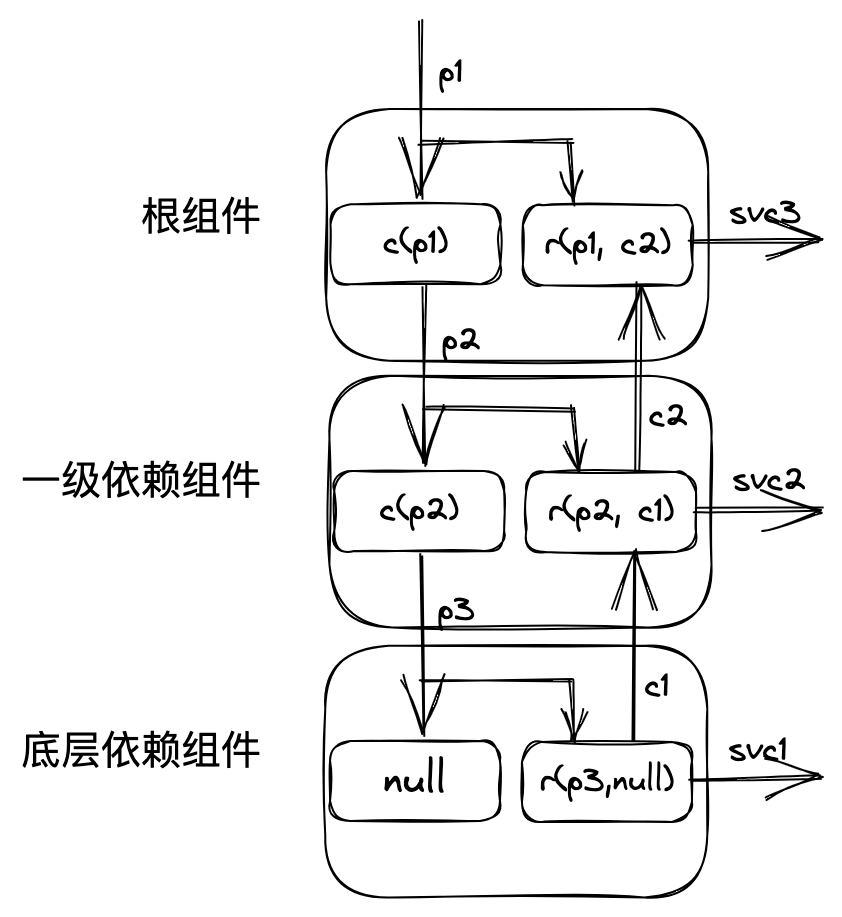
我们将双向配置传递及模版渲染过程建模为如下处理机:
- 某组件从父组件传递过来的pVal经由combo函数加工、传递到子组件上,完成配置的正向传递。
- 子组件将声明的配置cVal传递给该组件。
- 该组件将来自父组件的配置、子组件的配置、自身默认的配置以及用户传入的配置合并起来渲染模版,生成对应的服务编排文件。
- 根据该组件的配置声明,将cVal传递给其父组件,完成配置的反向传递。
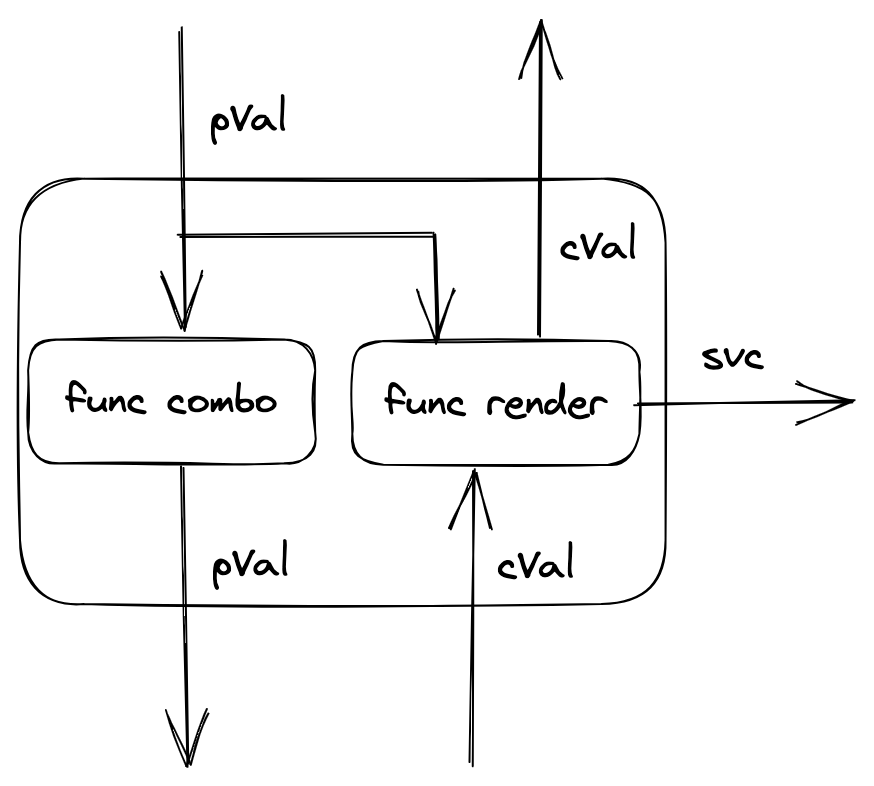
将每个处理机单元按照包依赖关系连接成管道,便形成了完整的编排解析器。在配置传递的过程中会不断地进行模版渲染以生成编排文件,最终可以编排出整个系统。
总结
服务编排以声明式的方式简化了微服务系统的部署,但生产环境下的交付平台远不能像docker compose一样只管理一个compose文件就行。这要求服务编排需要考虑包的编排复用、版本管理、依赖管理、模板编写、业务配置等诸多方面。只有做到编排足够灵活,私有化交付才可能高效进行。
该平台参考了go module、npm等包管理器的设计,将服务封装成一个个编排模板,并对其进行版本管理;结合依赖管理,该平台支持一键编排部署的能力;为了让我们的研发人员可以平滑地从旧的编排工具迁移到我们的交付平台上,我们扩展了编排模板引擎;参考helm的依赖传递模型,该平台提供了灵活的配置传递机制,并在此基础上增添了配置多播、配置加工等魔法,极力简化系统配置,隐藏配置作用细节,降低交付平台使用者的心智负担。