Golang 陷阱盘算

取自《100 Go Mistakes and How to Avoid them》及实践中踩过的坑。
问题梳理
代码和项目组织
变量覆盖(variable shadowing)
- 在内部块使用变量声明操作符
:=覆盖掉外部块声明的变量。 - 不会更改外部变量的值,一旦跳出内部块,变量随即消亡。
- 应避免同一变量跨不同作用域多次声明。
1 2 3 4 5 6 7 8func main{ a := 0 { a := 3 // 变量覆盖,如需更改外部变量a的值,需要使用=。 a++ } fmt.Println(a) // 0,内部块退出后变量值未发生变化。 }- 在内部块使用变量声明操作符
非必要代码嵌套
- 应尽量减少嵌套(循环、分支)层数。
- 尽可能早地 return,借助调转判断(flip the condition)减少嵌套层数。
- 借助 return、continue、break 等避免不必要的 else 子句。
init()函数的顺序- 包初始化后,先执行常量与全局变量的声明,再执行
init()函数。 - 不同包的
init()函数的执行顺序与包依赖顺序一致。 - 同一文件下
init()函数按定义顺序执行,同包不同文件下的执行顺序存在不确定性。 - 我们的代码逻辑不应该依赖
init()的顺序,避免调整包依赖关系导致非预期的行为。 init()可用于引入副作用,一般通过引入匿名包完成,如 db driver、pprof。init()函数存在错误处理受限、单元测试受限、状态依赖全局变量等问题。
- 包初始化后,先执行常量与全局变量的声明,再执行
Getters 与 Setters
- 不是 Go 语言的惯用法。
- 可以进行一些封装,如读时转换、写时校验、并发控制等行为。
避免接口污染
- 接口污染指代码中采用了不必要的抽象,使其难以理解。
- 接口抽象会增加单元测试的难度。
- 接口越大抽象性越差,越难以复用,可以适当组合细粒度的接口创建更高级的抽象。
- 接口应该被无意发现,而不应该被有意创建。我们在没有明确的原因时不应创建接口,除非我们确定需要它。
- 一些使用接口抽象的行为可以考虑使用泛型替代以提升可读性。
接口使用的限制
- 避免将接口定义在生产方,将是否抽象的决定权交给使用方。
- 尽量返回具体类型,避免限制使用方使用特定类型的抽象。
- 尽量避免使用any接口,因其可读性差,并且无法在编译时暴露出错误。
泛型
- 可以自定义接口限制泛型参数类型,如
compariable,如果定义类型是基础类型且包含~前缀,表明其支持底层为特定类型的 alias 类型。 - 类型参数不能用于方法参数,可以通过将类型参数应用于 receiver,或者使用反射来实现方法的泛型。
- 可以自定义接口限制泛型参数类型,如
类型内嵌
- 类型内嵌是一种组合,而不是继承。
- 如果内嵌多种类型,则这些类型不应存在相同签名的方法,否则会产生冲突。
- 类型内嵌主要是为了简便性。如果不希望把内嵌类型的全部方法提升到顶层类型时,不要使用内嵌方式。
- 类型内嵌可能引入一些不符合预期的行为,如内嵌的类型声明了 JSON Marshaler 等接口,那么顶层类型将无法使用默认的 JSON 序列化行为。
函数配置传递
- Go 没有定义默认函数的方法。
- 使用普通的结构体作为参数,默认值字段可能无法区分是用户传入了默认值还是没传入对应的字段值。
- Builder 模式可以通过构建方法链传递相关的配置,但这种方法无法及时返回错误,不得不推迟校验。
- 函数选项方式是 Go 的惯用法,核心流程如下:
- 定义一个未导出的 options 结构。
- 定义一个处理 options 的方法类型 Option。
- 定义一组配置 options 的具体实现。
- 函数参数传入 Option 不定参数,在内部定义一个 options 并迭代执行 Option 以固定相应的配置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25type options struct { // 第一步 port *int } type Option func(options *options) error // 第二步 func WithPort(port int) Option { // 第三步 return func(options *options) error { if port < 0 { return errors.New("port should be positive") } options.port = &port return nil } } func DoSomething(opts ...Options) error { // 第四步 var options options for _, opt := range opts{ if err := opt(&options); err != nil{ return err } } // use options }项目结构与规范
- Go 提出了项目结构的标准,这提供了一个通用的布局,可以让开发者避免花很多时间组织项目,但并不是强制规范。
- 包名的定义应该是有意义的,尽量简短,有意义的单个小写字母单词。避免使用 utils, common等包名。
- 最小化导出的内容以减少包间耦合,可以通过 internal 目录或者未导出元素进行限制。
- 一些需要序列化的结构体字段需要定义为可导出的。
- 尽量避免包名与变量名冲突,否则可能因为 variable shadowing 导致相应的包不可用,可以采用 package alias 或者 rename 与包同名的变量解决。
- 导出的元素都应该写文档,文档以注释的方式定义,但与内部注释的内容完全不同。函数文档应记录做什么,而注释记录怎么做。
- 包文档通常在
doc.go里添加。 - 需要采用 gofmt, goimports, golint, gofumt 等方式进行代码格式化与规则检查。
数据类型
基础数据类型
- 0开头的数字会被解析为八进制,通常采用
0o前缀显式定义八进制。 - 需要考虑整数溢出的行为,避免出现两个大正数相加溢出得到了个负数,可以使用
math/big处理大数操作。 - 浮点数使用
==进行比较通常会不精确,通常通过判断两个浮点的 delta 值是否足够小以判定两个浮点数是否相等,如assert.InDelta(t, math.Pi, 22/7.0, 0.01)。
- 0开头的数字会被解析为八进制,通常采用
切片
- 切片由一个指向底层数组的指针、长度和容量三个结构组成。
- 如果切片 append 元素时,底层数组已经满了,Go 会创建另一个具有二倍容量的数组,并将已经存在的元素拷贝过去再插入新元素。
- 避免低效率切片操作:
- 切片底层数组更换时,会引入拷贝大量元素和 GC 的开销,应尽量减少切片扩容的操作。
- 切片长度已知时,可以在初始化时显式声明数组长度
make([]int, 1000)初始化切片。 - 如果知道大致长度时,可以显式给个大致的容量值
make([]int, 0, 1000),避免出现频繁的扩容操作。
- 空切片与
nil并不相等,但其容量都为0,为避免错误的判断条件,尽量保证生产方返回nil,使用方使用切片长度len(s) == 0进行判断。 - 子切片与原切片共享底层数组,可以采用完整切片表达式
s[low:high:max]来声明切片的容量。 - 可以采用
copy()或者通过append([]int{}, s...)方式进行切片元素深拷贝。 - 经常踩的坑:
- 子切片 append 元素覆盖,即子切片的末尾未触及底层数组的边界时,往子切片 append 元素时,会覆盖底层数组对应的元素,从而影响其他切片的值。在刷题时进行 dfs 传入切片回溯时会经常出现此类问题,可以采用切片深拷贝的方式解决。
- copy 方法拷贝元素数目是 src 与 dst 的最小的长度,且 dst 是第一个入参,src 是第二个入参。
- 切片会导致底层数组不会被 GC,导致内存一直不会被释放。可以通过拷贝元素的方式替代短切片。
- 切片作为入参时采用的是值拷贝,即如果给切片变量赋新值则不会改变原切片;如果给切片中的元素赋新值,相当于改变底层数组中的元素值,会对原切片造成影响。
- 切片并行 append 会产生 data race,并行给不同 index 赋值不会产生 data race。
Map
- Map 底层由 buckets 组成,且 bucket 数目不会减少。
- Key/Value 的值如果超过 128 字节后,Go 会存储一个指向 key/Value 的指针。
- Map 是并发不安全的,即便操作不同的 key 也会产生 data race。
- 写 map 前需要保证 map 已被初始化,为了避免扩容产生的拷贝开销,建议初始化 map 时指定容量,如
make(map[int]int, 10)。 - 值为
struct{}类型的默认值不分配内存空间,如果想要实现Set的功能时,建议采用空结构做为值类型。 - Map 迭代的顺序是不确定的。
- 避免在迭代过程中向 map 中插入元素,这会为后期的迭代引入不确定性,如果希望边迭代边插入,可以考虑拷贝一个新的 map,确保迭代和插入是两个完全隔离的 map。
控制结构
- 循环
- range 循环是对目标进行拷贝,如果对 range 的元素进行修改,则只会更新拷贝而不是元素本身。如果希望更改生效的话,需要保证目标值是指针类型,或者采用索引复制的方式进行更新。
- range 只会在 loop 前执行一次表达式,并对其进行深拷贝迭代。不要在 range loop 中为切片添加元素,避免产生非预期的行为。
- 循环变量是个指针,在迭代过程中会对元素迭代地进行引用。在并发访问循环变量的闭包时会访问到不确定的元素。解决办法是采用变量拷贝或者将闭包改造成函数传参。
- loop 时不要使用 defer 命令,因为在 loop 结束后 defer 并不会执行,只有在函数返回时才会执行,long-running loop 会导致严重的内存泄露。
字符串
- 字符串是不可变的,所有对字符串的更新操作都是拷贝,而不是原地更新。
- 一个 rune 是一个 unicode 码字。
len(str)返回的是 bytes 的长度,而不是 runes 的长度。- 使用 index 循环(
for i:=0; i<len(s); i++)迭代的是每个 byte,使用 range 循环(for i := range s)迭代的是每个 rune。 TrimLeft/TrimRight移除所有与给定字符串匹配到的每个字符;TrimPrefix/TrimSuffix移除的是匹配的完整字符串。- 使用
+连接字符串的效率很低,可以采用strings.Builder进行连接以提升性能。 - 通过显式类型转换对 []byte 与 string 转换的效率很低,可以采用
bytes包直接操作 []byte(所有strings包提供的函数都有),减少二者的相互转换。
函数和方法
值接收者和指针接收者
- 对于值接收者,Go 拷贝值将其传到方法中,对对象的修改只在方法内生效,原始对象值不变。
- 对于指针接收者,Go 拷贝指针到方法中,对接收者的修改会影响到原始对象。
- 使用指针接收者的场景
- 需要修改接收者的方法。
- 接收者包含无法被拷贝的字段。
- 对象 size 很大,使用指针接收者可以避免庞大的拷贝开销。
- 使用值接收者的场景
- 要求接收者不可变。
- 接收者类型是 map/function/channel。
- 接收者是基础类型(int/string/float64)。
- 当不确定使用那种方式时,无脑选择指针接收者。
返回值参数
- 核心目的是增强代码可读性。
- 声明返回类型参数时,可以返回裸的 return,但这不是使用返回值参数的理由,也不推荐这种方式返回。
- 使用裸 return 时,要注意 variable shadowing 的问题。
方法是函数的一个语法糖,接收者作为函数的第一个参数。
1 2 3 4 5 6 7 8func Bar(foo *Foo) string { return "bar" } // 上述函数的语法糖。 func (foo *Foo) Bar() string { return "bar" }空指针与空接口不一样,空指针具有类型值,因此不等于 nil,空指针可以作为接收者正常调用。
参数传递文件名是一个糟糕的方式,因为其难以进行单测,且可复用性差。建议采用
io.Reader,io.Writer替换。defer 参数执行时机
- defer 参数为值变量时,会立即执行,不会感知函数返回前的赋值。
- defer 参数为闭包时,在函数执行完成前的赋值会被 defer 感知到。
- defer 参数为函数时,实参变量会立即执行,不会感知函数返回前的赋值。
1 2 3 4 5 6 7 8 9 10 11func main() { i := 0 defer fmt.Println("传递变量:", i) // 传递变量: 0 defer func(){ fmt.Println("传递闭包:", i) // 传递闭包: 1 }() defer func(i int){ fmt.Println("函数实参:", i) // 传递实参: 0 }(i) i++ }
错误管理
Error wrapping
- 常见用例
- 添加额外的上下文。
- 标记一个 error 为特定的错误。
- Go 1.13 可以使用
%w标记 wrapping。 - 引入潜在的耦合,因其允许使用方接入到 source error。
- 常见用例
错误判断
- 判断错误值,使用
==进行精准判断,如if err == io.EOF。 - 递归判断错误类型,使用
error.As递归地 unwrap error,判断某个 error type 是否出现在错误链上。其第二个参数一定需要是指针类型,否则会 panic。 - 递归判断错误值,使用
error.Is递归地 unwrap error,判断某个 error value 是否出现在错误链上。
- 判断错误值,使用
本质上打印 error 日志也是处理错误的一种方式,因此返回错误与打印日志二者只选其一,避免对错误的多次处理(打印)。
为增强代码可读性,不要直接忽略返回的错误,而是将其显式分配到一个空标识符上(
_),以表示我们不关心这个错误。
并发控制
并发与并行
- 并发是同时处理多个任务,但同一时间最多只做一件,通过调整任务的顺序提升多任务处理效率。
- 并行是同时做多件事,需要利用多个核。
Go scheduling
- Goroutine 是应用级线程,初始大小为 2KB,并按需扩展。
- Goroutine 调度由 Go runtime 完成,不需要切换内核线程上下文。
- GMP 原理
- 全局队列、work stealing。
- P 的数量与
GOMAXPROCS一致,M 的数量一般更多一些。
- Go 1.14之后支持了抢占式调度,即使某个 goroutine 一直处于非阻塞状态,也不会饿死其他 goroutine。
- 由于 goroutine 切换也存在开销,因此一些本身开销较小的逻辑并发处理后反而会更慢。
Mutex vs Channel
- Go 提倡通过通信来共享内存,但这并不意味着鼓励用 channel 替代 mutex。
- 如果想共享状态,建议使用 mutex 排他地接入到共享资源上。
- 如果想使用信号同步或者并发顺序处理,建议使用 channel 进行通信。
Data race vs race condition
- Data race
- 多个 goroutine 同时接入到一个相同的资源,并且其中至少存在一个写操作。
- 可以通过原子操作、使用 mutex 排他接入或者使用 channel 通信机制进行同步接入。
- Race condition
- 行为受事件发生的顺序影响而不受控,存在不确定性。
- Data race
Context 机制适用于并发控制,级联控制,超时控制,跨边界传值等场景。
并发控制在实践中注意的问题
- 当 goroutine 开始时,需要明确何时他会停止,以避免其持有的资源发生泄露。
- 避免在 goroutine 中使用循环变量,可以通过以下两种方式获取循环值。
- 创建一个本地变量。
- 使用函数传参替代闭包。
select并不像switch一样按顺序匹配子句。select 会随机从满足条件的 case 中挑选一个操作,这主要考虑避免饿死其他 channel 的场景。- channel 用作信号同步时,建议使用 chan struct{} 传递空结构体,以减少内存分配。
- nil channel 可以永远不会被
select选中,因此在同时操作多个 channel 时,如果其中某个已关闭,可以将其赋值 nil 以移除对应 case。 - buffered channel 用处十分有限,最常用的是工作池与并发限速两个场景。同步一般使用 unbuffered channel。
- 切片 append, map 并发读写会引起 data race。
sync.WaitGroup用作同步控制- 不应在 goroutine 里面执行
Add(1),避免提前结束。建议使用以下两种方式:- goroutine 数目预先可知时,建议在 for 循环前执行
Add(N)。 - goroutine 数目未知时,建议在 for 循环内,goroutine 前执行
Add(1)。
- goroutine 数目预先可知时,建议在 for 循环前执行
Done()应该在 goroutine 退出前执行,推荐使用defer。- 如果希望在并发时,某个 goroutine 失败后终止此次并发过程,建议使用
errgroup尽早终止。
- 不应在 goroutine 里面执行
- 如果希望向多个 channel 重复发送通知,可以使用
sync.Cond,不过一般这种场景可以被 context 机制覆盖。 - channel 关闭方应为唯一的发送方,不应由接收方关闭。当有多个发送方时,需要同步机制以决定何时由谁来关闭。
- 永远不要复制 sync 类型值,避免复制出多个实例破坏排他性。
标准库
time
time.Duration是 int64 类型,其值的单位为ns。在使用时,用包内自带的度量常量避免出错(如time.Seconds * 2)。time.After创建的资源会在超时后自动释放,但在超时前,所占用的内存无法释放。要避免在循环中使用引起大规模内存泄露。time.Timer提供了Reset(time.Duration)方法重置超时时间,可以解决time.After潜在的内存泄露问题。其底层实现也利用了time.After。
json
- 类型嵌套时,当内嵌的类型实现自己的
json.Marshaler接口时(如time.Time),会提升到父类型上,从而使得父类型不满足默认的序列化规则。 - 值为 any 类型的 map 在
json.Unmarshal()时会按 json 默认的数据类型反序列化,而数字在 json 中都为浮点数类型,所以对应字段 any 所涵盖的实际类型为 float64。
- 类型嵌套时,当内嵌的类型实现自己的
sql
sql.Open()不保证会建立连接。对于某些 driver 而言,仅创建客户端句柄,真正连接会在使用时延迟建立。如果想确认数据库是 reachable 的, 可以在sql.Open()生成的*sql.DB上调用Ping()方法。*sql.DB并不表示单个的数据库连接,而是个连接池。建议对连接池参数进行配置,以提升性能:SetMaxOpenConns:设置最大打开连接数。在生产环境下需要设置,以确保底层数据库能处理得过来。SetMaxIdleConns:设置最大空闲连接数,默认值为2。需要根据请求数据库的并发量调整此配置。SetConnMaxIdleTime:设置连接最大空闲时间。应用面临大量突发请求时,应将其配置较小的值,避免大量空闲连接驻留在内存中。SetConnMaxLifetime:设置连接最大打开时间。当连接到负载均衡器时,需要设置生存时间,以期对负载进行再均衡。
- 如果 SQL 声明需要重复执行,应该使用 prepared statement (
db.Prepare) 以提升效率与安全性。 - 在迭代获取 sql 结果时,需要判断迭代过程是否发生了错误,通过检查
row.Err()是否为空来判断。 sql.Rows使用完毕后需要显式Close掉,避免连接泄露而无法放回连接池中。
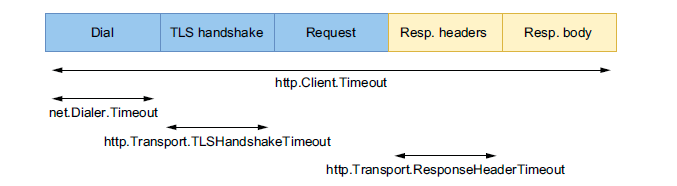
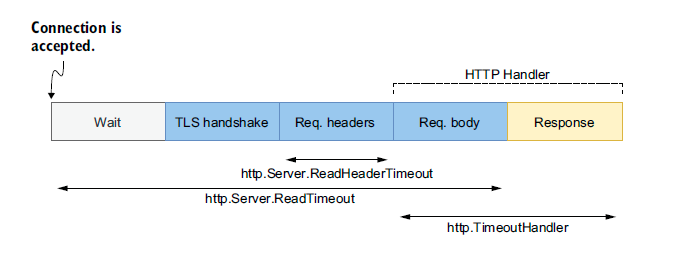
http
http.Response.Body在使用完毕后需要显式Close掉,避免内存泄露。http.Error执行后并不会终止后续处理,因此需要手动添加return。- 不应使用默认的 http client,因其没有设置任何 timeout。
- Http client 与 server 所支持的 timeout 如下:

Http client timeout 分类
测试
- 测试金字塔自底向上为单元测试、集成测试、e2e测试。
- 可以使用 build flag(如
//go:build integration)筛选出执行哪些测试。指定 tag 时,声明对应 build tag 的测试文件及没有声明 build tag 的文件会被执行。 - 可以使用
t.Skip()跳过某些特定的测试,其粒度为函数级,而 build flag 的粒度是文件级。 -race参数可以检测出函数是否存在 data race,但其性能开销较大,应尽在本地测试或者在 CI 中添加。- 对于不存在依赖关系的测试函数,可以使用
t.Parallel()并发执行提升效率,执行顺序为先依序执行顺序测试,再执行并发测试。 - 单元测试的规范是表格驱动。
- 可以借助
httptest包对 http server 进行模拟测试;借助iotest对 IO 进行模拟测试。
优化
大多数场景下,代码可读性强要比优化后更复杂、不易理解的代码更好。
按重要性排序:准确性 > 清晰性 > 简洁性 > 高性能。
CPU cache 主要包括 L1、L2、L3 三级,分别在逻辑核内独享、在物理核间共享、在 CPU 间共享。
Cache line 优化使得每次读取变量时会读取一整块,主要利用了局部性思想:
- 空间局部性:附近的内存位置会被访问到,如数组访问。
- 时间局部性:相同内存位置会被重复访问,如变量访问。
- 二维数组行优先遍历比列优先遍历性能好,可以使用空间局部性进行解释。
结构体字段未对齐时会引入 padding,占用额外的内存空间,建议结构体字段按照类型大小进行降序定义以实现数据对齐。
堆上内存分配的开销较大,需要通过 GC 来释放空间;栈可以自动清理,是单个 goroutine 独有的本地空间。要尽量避免在堆上分配内存。
逃逸分析是指编译器确定变量分配到堆上还是栈上。常见的分配到堆上的 case 包括:
- 函数返回指针,指向其内部的变量(sharing up)。
- 全局变量。
- 发送到 channel 上的指针。
- 尺寸过大的本地变量。
- 尺寸未知的本地变量,如
s := make([]int, n)。 - 切片 append 触发底层数组重新分配。
io.Reader传入切片而不是返回切片,目的之一是避免非必要逃逸到堆上的情况。如果需要频繁分配相同类型的对象,建议使用
sync.Pool节省重建对象的开销。内联发生在复杂度低的函数上,可以移除函数调用的开销,允许编译器做更深层次的优化。
后向兼容性
避免产生 breaking change 的宗旨:只添加,不修改,不删除。
函数的兼容性
- 函数/方法签名增加可变参数可以保证函数/方法调用兼容性,但无法保证后向兼容。如函数作为另一个函数的参数,方法实现了某个接口等。
- 如果函数希望支持 context,需要新增一个带 context 参数的函数,并将相关逻辑移到新函数里,原函数调用新函数避免代码重复。如
db.Query()/db.QueryContext()。 - 如果函数预期未来会添加很多配置,可以使用如下方式:
- 使用配置结构体定义函数。如
func Dial(network, addr string, config *Config) (*Conn, error)。 - 使用options可变参数定义函数。如
func Dial(network, addr string, opts ...Option)(*Conn, error)。 - 改造成配置结构体的方法。如
func (*ListenConfig) Listen(ctx context.Context, network, address string) (Listener, error)
- 使用配置结构体定义函数。如
接口的兼容性
- 如果不想让别人实现你的接口,可以在接口中添加一个未导出的方法。
- 如果接口的定义方希望新增一个方法,则必须创建一个新的接口,避免在原接口上直接添加,破坏兼容性。
- 如果接口的使用方接口希望新增一个方法,可以使用类型断言的方式判断传入接口的具体类型是否扩展了新方法。如
1 2 3 4 5 6 7 8 9 10 11 12package tar type Reader struct { r io.Reader } func (r *Reader) Read(b []byte) (int, error) { if rs, ok := r.r.(io.Seeker); ok { // 判断 Reader 是否实现了 io.Seeker 接口。 // Use more efficient rs.Seek. } // Use less efficient r.r.Read. }结构体兼容性
- 对于导出的结构体,添加新字段和删除未导出的字段一般不会破坏兼容性。
- 在一个可比较的结构体中,添加一个不可比较的字段会破坏某些场景的兼容性,如使用
==判等,结构体值用作 map 的 key。 - 为了使定义的结构体不可比较,以避免上述的不兼容性,可以嵌入一个函数字段,如
1 2 3 4 5 6 7type doNotCompare [0]func() type Point struct { doNotCompare X int Y int }
实践反思
init函数与全局变量
背景描述
命令行工具希望添加一个调试 flag 来开启 http 嗅探中间件,以在 RoundTrip 中打印 request 与 response 信息。
具体实现
命令行工具库 cobra 通过 init() 函数将用户输入的 flag 绑定全局变量中。而我们试图使用该变量开关创建全局 http.Client。所有的 http 请求使用该 client 发起。
问题及原因
该 flag 未生效,无法控制 RoundTrip 的类型,因为 http client 的初始化早于 init() 函数,client 在变量绑定前就已完成初始化,因此使用的是该 flag 的默认值。
解决方法
将获取该 http client 的方式由全局变量改成函数获取,在请求发起时可以确保init()执行完毕,flag 成功绑定,可以正常控制是否开启嗅探中间件。
浮点数 Quota 调度
背景描述
在容器资源调度时,资源 Quota 粒度为浮点数。
具体实现
判断剩余资源是否大于申请资源,如果大于则进行资源分配并对申请资源进行扣除,如果小于则分配失败。
| |
问题及原因
当资源理论上恰好够完全分配时,实际调度中存在调度到最后一个容器时资源不足的情况。比如总 quota 为1,申请的资源为 50 container * 0.02 quota。
由于浮点数存储及操作都只是近似的,因此在做严格比较时,会出现非预期的情况,即调度到容器时,剩余的 quota 略小于申请的 quota。
浮点数非精准计算举例如下:
| |
解决方法
方法一:使用近似比较替换严格比较,确保误差小于 quota 分配的分度值。
| |
方法二:将浮点数字段改造成 Quantity 类型。
Quantity 提供了浮点数比较的方法,同时也支持解析基本量级单位,既增强了可读性,又缩减了浮点数使用的场景。如 0.01 => 10m。
考虑到重构会带来兼容性上的问题,我们实际采用了方法一。但作为调度模块而言,使用 Quantity 更科学,更通用。
Track Map 爆内存
背景描述
对于视频流人脸检测,我们对每一帧进行检测,并将同一人脸框加入到一个 track 中以进行后续择优。
具体实现
我们对于检测出的每个人脸,构造一个 track,使用 map 存储所有的track。生成一个 uuid 作为 key 进行索引。当该物体离开视频后,处理后删除掉相应的 track。
| |
问题及原因
应用运行一定周期后出现 OOM,且反复出现。
由于 map 删除 keys 后并不会完全释放掉所占内存,而目标数目相对比较庞大,track 的创建与删除的规模较大,引起了内存泄露。
解决方法
定期拷贝 track map,频繁创建删除的 map 会被 GC 掉。
| |
Protobuf 客户端与服务端的兼容性
背景描述
客户端与服务端使用 gprc gateway 进行通信。
具体实现
客户端使用 protojson 进行反序列化到 proto 结构体中。
| |
问题及原因
服务端在 proto 中新增一个字段后上线,旧版本客户端再请求时出现不兼容,报错 proto: (line X:Y): unknown field "someField"。
此序列化方法在校验时,发现 json 中存在,但 proto 中不存在的字段会抛出 unknwon field 异常,除非显式指定 DiscardUnknown Options
默认的 Unmarshaler 居然会破坏后向兼容性,实乃大坑。
解决方法
添加 DiscardUnknown 选项。
| |
切片 append 覆盖
背景描述
刷算法题:求给定整数集合S的所有子集。
具体实现
使用递归处理切片的方法:
| |
问题及原因
当用例为 S=[9,0,3,5,7]时,返回结果出错。

可以看到,存在两个子集中重复出现了9,而排序后9是最后一个元素,因而初步怀疑是数组 append 覆盖的问题。
为了验证这一猜想,在 for 循环的前后打印了 subResults 的结果,最后一轮的结果如下:
| |
显然 append 执行后,将 [0,3,5,7] 最后一个元素覆盖成了9。
回到代码中,我们看到 subResults 复用了上一轮递归返回的切片,并在循环中对这些切片进行了 append 操作。当遍历到 [0,3,5] 时,此时底层数组为 [0,3,5,7],对前者 append 9 时,由于 length < capaticy,7会被9覆盖掉。本质原因是上一轮迭代的结果与本次迭代中存在复用了同一底层数组的切片。
解决方法
为了避免 append 覆盖问题,需要避免上次迭代的切片与本次迭代的切片复用同一底层数组。
代码段中的注释给出了两种解决方案:解决方案1将上一轮迭代的切片进行深拷贝;解决方案2将本轮迭代的切片进行深拷贝。两个方案都使得某一侧的切片结果分配到另一个底层数组中。
io.Reader 读取不完整。
背景描述
使用 oras 将多个文件组织成 OCI Artifacts 传到 OCI Distribution 上。
具体实现
在从 registry 上拉取 image manifest 时,会先根据 image index 获取到 manifest descriptor,这个 descriptor 记录着 manifest 的位置及大小。
创建指定大小的切片,并传入到 http.Response.Body.Read() 中以获取 image manifest。
问题及原因
当 image manifest 过大时,从获取切片中进行 unmarshal 解析时,报错 invalid character '\x00' in string literal,即未获取到完整的 manifest。
因为在 Read() 时不保证一次将所有的内容都读到切片中,当 Reader 内容过大无法一次读出时,会出现一次读取的内容不完整的现象。
解决方法
使用 io.ReadFull() 替代 Reader.Read(),以保证可以将 Reader 中相应尺寸的内容完整读到切片里。具体解决方法为:https://github.com/oras-project/oras-go/pull/142
引用
- 《100 Go Mistakes and How to Avoid them》
- Keeping Your Modules Compatible