大模型预训练数据处理

数据质量决定了模型的质量,对海量训练数据进行高效清洗是 AI 工具链中至关重要一环。
预训练与 SFT 是大模型训练的两个核心步骤,前者通常使用海量的非结构化数据进行无监督训练,后者使用已标注的指令数据进行微调, 本文主要针对海量预训练数据的处理方案展开调研。
数据处理 Pipeline
预训练数据一般具备如下特点:
- 来源广,一般来源于网络爬虫,B 端提供数据集,开源数据集等。
- 数据量大,通常是 GB/TB 级别的规模。
- 数据格式多样,既包括 pdf、word、文本等非结构化数据,又包括 json、xml、csv 等结构化数据。
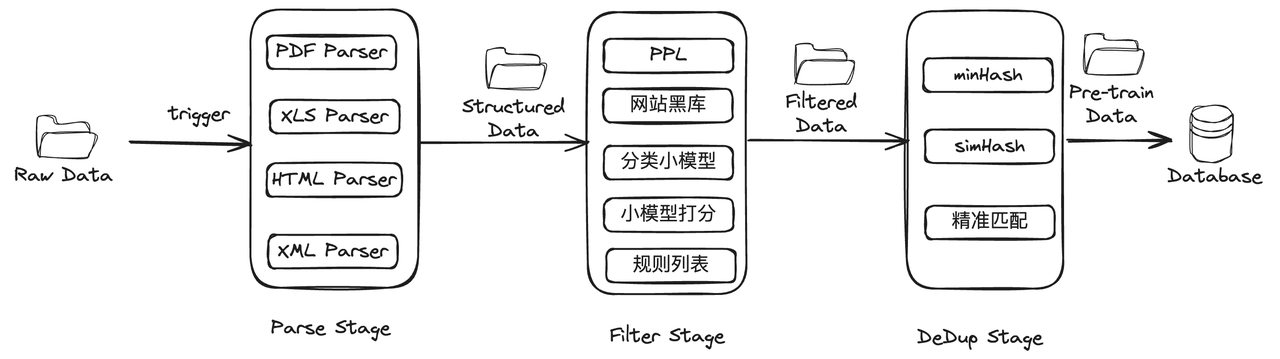
考虑到上述数据特点,预训练数据处理通常包括文本解析、过滤、去重三个阶段。
为了提升数据处理的灵活度和可扩展性,采用基于算子的 Pipeline 方式进行处理。 每个阶段可能划分为很多个规则(又称算子),每类算子定义相同的输入输出,并可以灵活组合相连构成一条数据处理流水线。类比于传统流水线系统:
- 每个算子是最小粒度的处理单元,类似于流水线系统中的 Step。
- 处理阶段是一组算子的逻辑集合,类似于流水线系统中的 Stage/Task。
- 完整的处理流程将各个算子串联起来,类似于流水线系统中的 Pipeline。
批处理 vs 流处理
批处理与流处理是大数据中两个典型的处理方式。批处理通常处理固定的、有界的数据集,一般用于离线计算;而流处理通常处理不固定的、无界的数据,一般用于实时计算。 对于预训练数据,批处理与流处理方案对比如下:
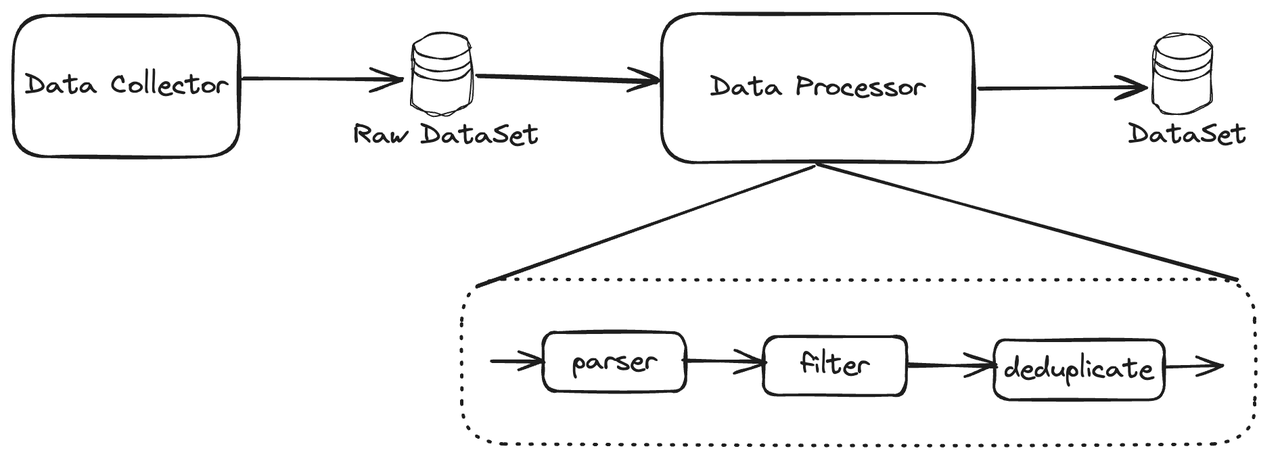
批处理
- Data Collector 是 Data Processor 的前驱任务,前者采集到的数据作为后者的输入。
- Raw DataSet 可以通过分片的方式被多个Data Processor 进行处理。
- 可以使用 MapReduce、Spark 等框架实现。
流处理
- Data Collector 与 Data Processor 可以并行进行,整体延时短。
- 对于一些全局处理(去重)可能仍需要批处理。
- 可以使用 Flink、Spark Streaming 等流处理框架实现。
考虑到预训练场景的高吞吐量等需求,我们采用离线的批处理计算方式。
分布式数据处理
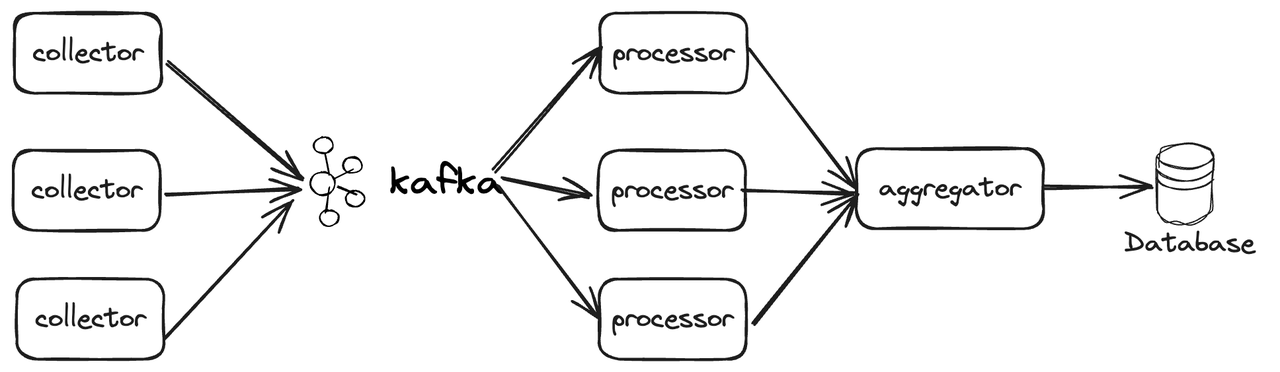
考虑到预训练数据规模比较大,因此需要使用多机进行分布式处理以提升处理速度。
分布式需要考虑以下几个问题:
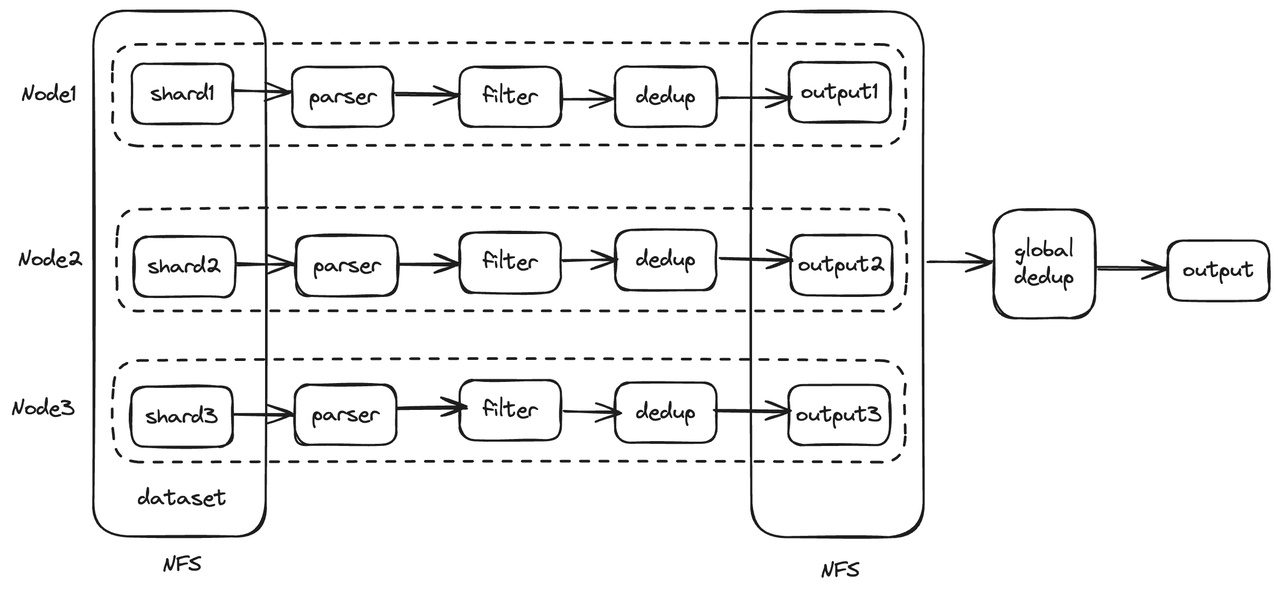
- 数据接入问题,每个节点都需要能够访问到训练数据,通常数据会存储在分布式存储系统上,考虑到 B 端交付场景,我们采用 NFS 存放完整数据。
- 数据分片问题,每个节点都需要处理一部分数据,高效的数据划分需要考虑集群中各个节点的差异性。
- 数据收集问题,有些操作需要在全局数据集上进行(比如全局去重),需要将各个处理后的分片收集起来整体处理。
考虑到上述问题,预训练数据的分布式处理流程如下:
开源解决方案
大数据处理多采用 Apache 提供的 Hadoop、Spark 等分布式计算框架,但这些框架比较重,不适合私有化交付。我们目前的私有化交付都是基于 K8s 容器平台,因此我们探索一些云原生相关的 Pipeline 开源方案。
Data-Juicer
data-juicer 是由魔搭开源的 LLM 一站式数据处理系统,提供了大量数据处理、分析、可视化工具包。
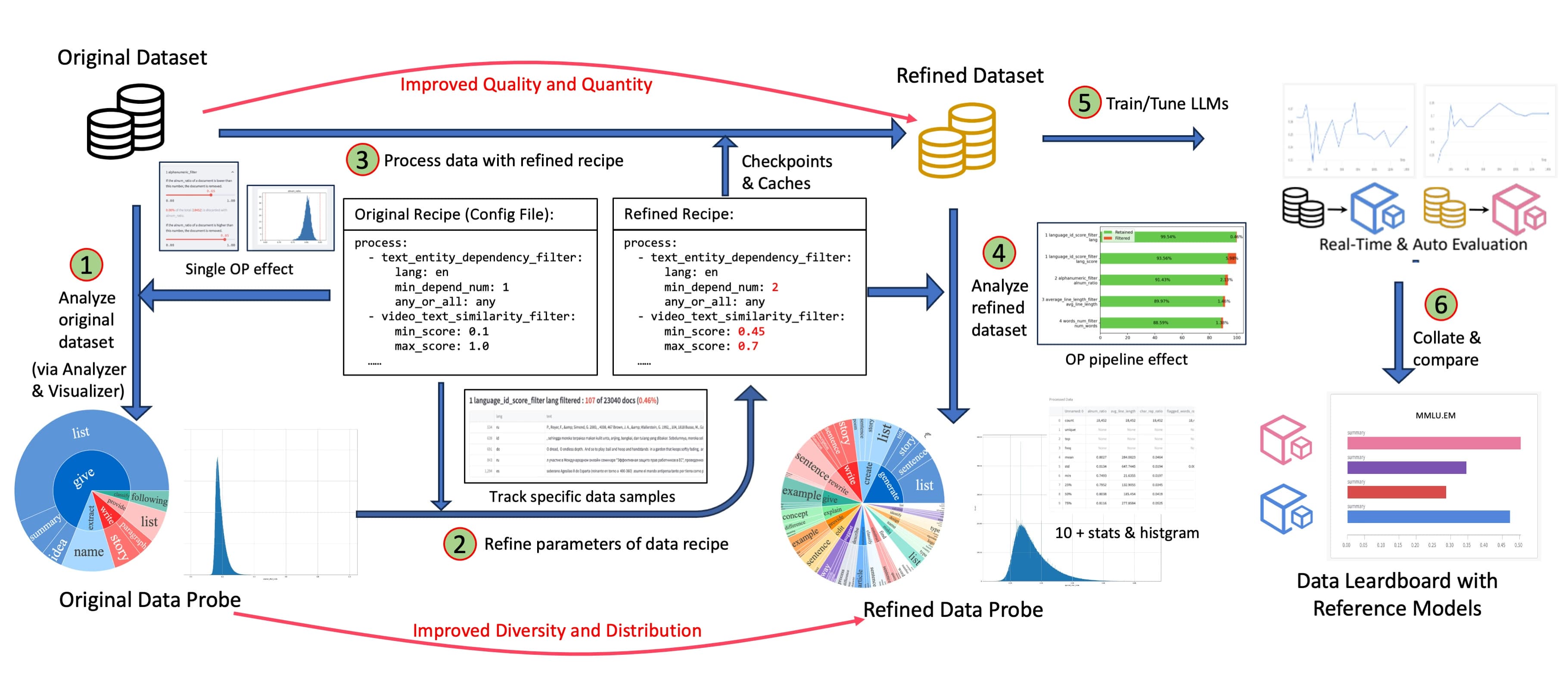
Data-juicer 具备如下特点:
- 通过配置定义 pipeline,使用简单,便于进行版本管理。
- 预置大量通用算子,分为 Formatter、Mapper、Filter、Deduplicator、Selector 五类,覆盖多种数据处理需求。
- 框架使用 python 实现,方便结合一些小模型进行处理。但环境依赖较为复杂,通过容器交付时镜像 size 过大。
- 自定义算子流程较为简单。但其存在语言限制,仅支持在源码侧更改,交付成本较高。
- 结合 HuggingFace Datasets 进行数据变换,基于内存映射与磁盘存储,使得小内存环境可以加载大量数据,且性能很好。
- 框架提供了 cache 管理机制与 checkpoint 机制,大量减少重复计算。故障后可以在断点处继续处理,但代价是存储了大量中间数据。
- 可以与 Ray 集群深度结合,支持分布式数据处理。
使用配置文件定义数据处理 Pipeline 示例如下:
| |
此框架设计简单,专为 LLM 训练数据处理而生,十分适合我们的处理场景,但是其存在如下两个问题:
- 私有化场景下扩展性较差,需更改源码并重新构建镜像使用。
- 分布式方案需结合 Ray 框架,此框架存在 ShadowRay 漏洞,被禁止在私有化场景使用。
为解决这些问题,我们不得不寻找更通用的分布式 Pipeline 方案。
Tekton
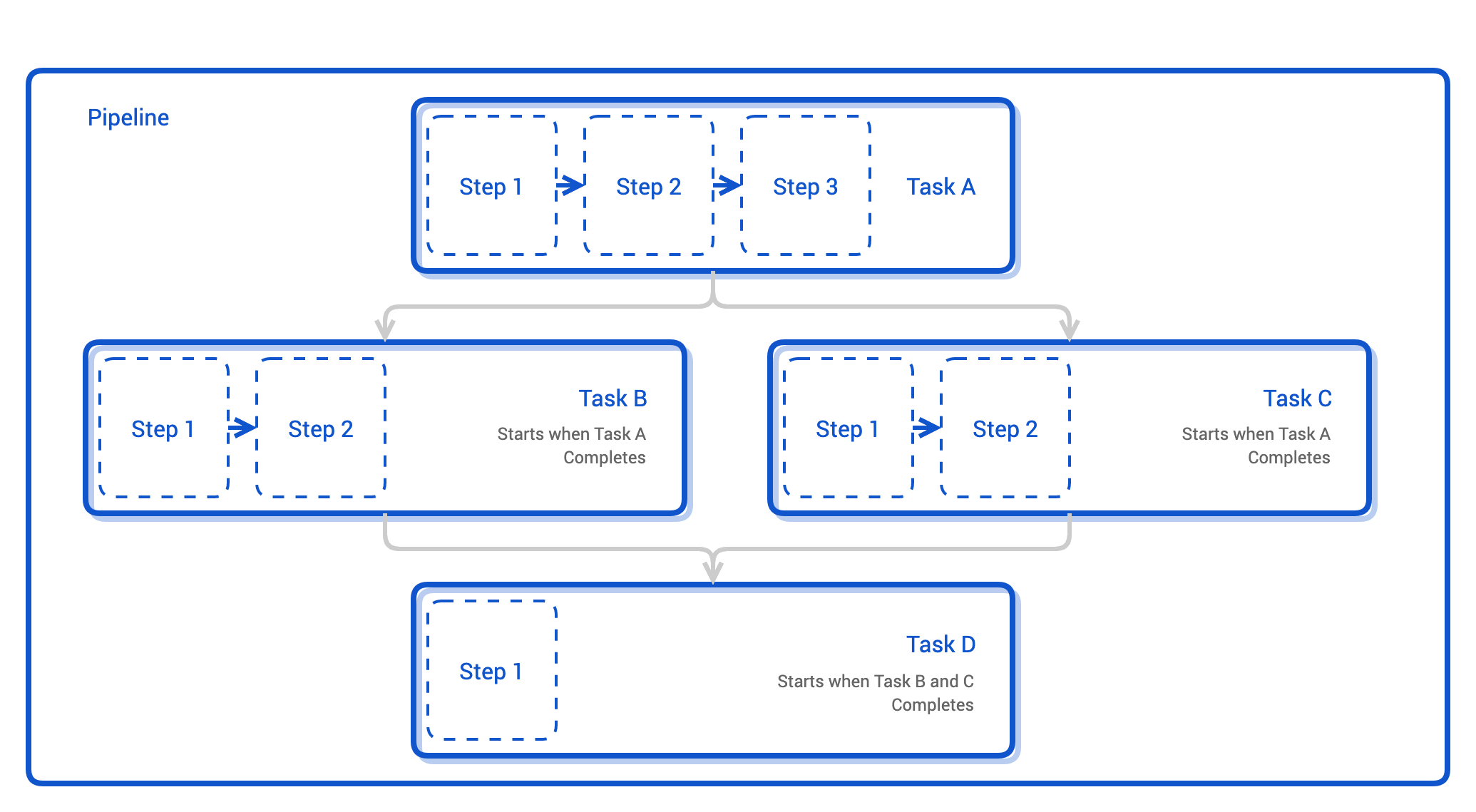
Tekton 是目前最火的云原生 CI Pipeline 系统,它引入了多种 CRD 灵活地定义 Pipeline:
- Task:包含若干顺序执行的 Step,Task 会在一个 Pod 内按顺序执行各个 Step,一个 Task 内的 Step 可以共享数据。
- TaskRun:运行 Task 的实例。
- Pipeline:包含若干 Task,并需声明 Task 的依赖关系,不存在依赖关系的 Task 可以并行运行。Pipeline 可以复用 Task。
- PipelineRun:运行Pipeline的实例。
定义 pipeline 的配置示例如下:
| |
Tekton 基于 K8s,因此天生具备分布式能力,但其并非为数据处理而设计,因此需要在上层自行实现数据分片、数据聚合以及分布式场景中常见的故障转移、负载均衡等逻辑。
Pachyderm
Pachyderm 是一款主打数据版本化和数据血统的云原生自动化数据处理平台,其具备如下特性:
- 数据驱动 Pipeline,数据变化时自动触发。
- 不可变数据血统和 git-liked 版本化管理。
- 自动化数据分片,基于 K8s 的自动扩容与并发处理。
- 基于对象存储的自动化去重。
- 支持在多种公有云上与本地部署。
- 为数据版本与数据血统提供可视化界面。
- 支持 checkpoint、重试、故障转移等能力。
Pachyderm 提出了以下核心概念:
- Repo:Pachyderm 管理的数据集,基于S3 + postgresSQL 实现数据的版本控制。
- Datums:数据集的分片,分片加入队列中供 workers 挑选处理.
- Pipeline:使用 transform 容器处理某个 repo 中的数据,输出到另一 repo,通过声明 repo 的关系形成 DAG。
- Job:版本化的 K8s 资源,用于描述一个 Pipeline 的执行。
- Task Parallelism:一个 Job 将数据集拆分成若干片,被多个 worker 并行处理。
- 版本化:Repo、Job 均以类似 git 方式管理起来,便于溯源。
Pachyderm 使用 filepath glob 对数据进行分片,简单灵活。
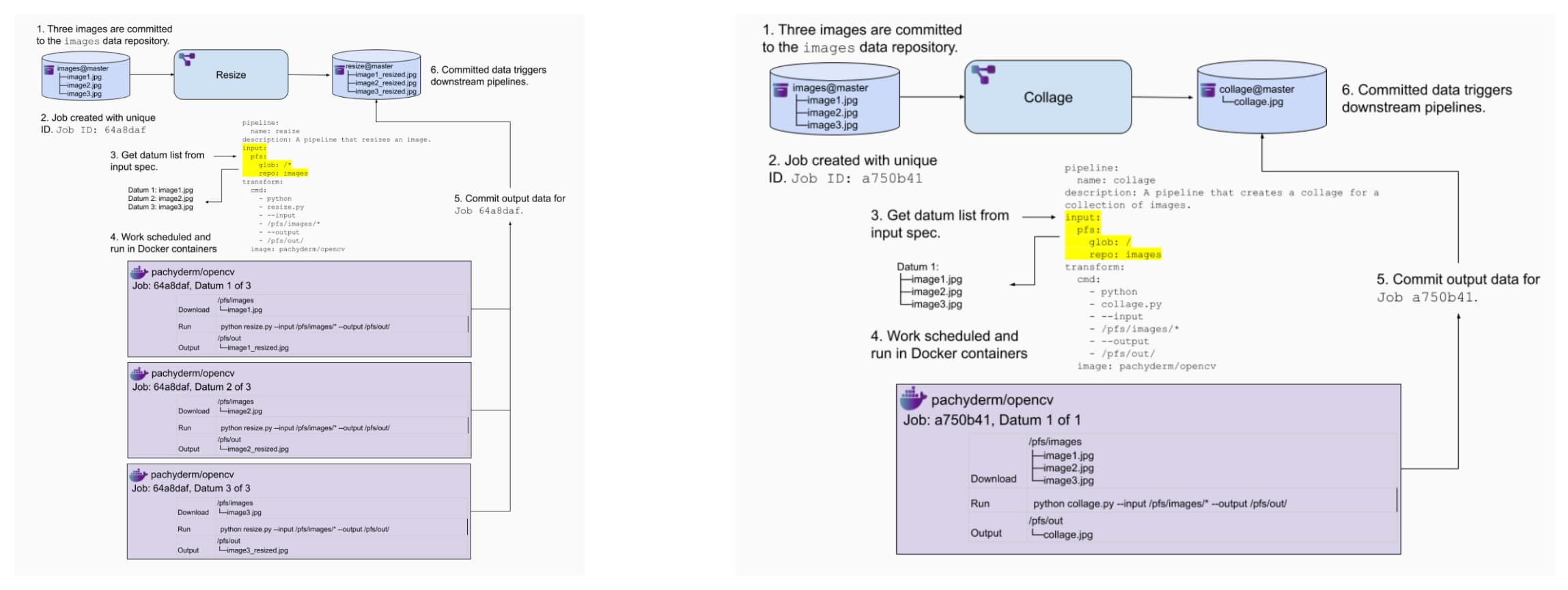
上图可以与我们分布式处理的流程图完美契合,分布式处理时进行分片,全局去重时不分片。
Pachyderm 中 DAG 的定义并不向 Tekton 那么直观,它所定义的 Pipeline 是声明一个输入、输出与转换关系的配置,本质是一个算子的定义:
| |
然而,Pachyderm 存在以下两个问题:
- 社区版限制 Pipeline 个数上限为16,任务并行度上限为8。
- 无法对大文件进行分片。
方案选择
综合上述的调研,我们选择 Pachyderm + Data-juicer 的方案来实现数据处理系统,原因如下:
- 部署方式基于 K8s,私有化交付效率高。
- Pachyderm 供了简易的、语言无关的算子定义方式,可扩展性强。
- Pachyderm 数据处理通用性强,可以将模型、配置、数据集放在 Pachyderm 上进行版本化管理,并将 Pipeline 应用到数据处理、预训练、SFT、推理等各个阶段。
- Data-juicer 预置大量了算子,开发成本低,避免大量离散的算子消耗 Pipeline 数量。
我们将 Data-juicer Pipeline 配置(process-config/dedup-config)和数据集(jsonl-data)上传到 pachyderm 中,利用 Data-juicer 进行处理,效果图如下: