SFT 指令数据生产

SFT 需要大量人工标注数据,而合成数据正逐步解放数据标注生产力。
算法?算力?数据!
ChatGPT 掀起了大模型的研究浪潮,将传统 AI 推向了 AI 2.0 的时代。AI 的三大要素:算法、算力、数据又再一次活跃在技术领域中。
ChatGPT 高质量的对话带火了 Transformer 神经网络结构,它所蕴含的两个核心特性大幅提升 NLP 的表达效果:注意力机制使得模型在文本处理时可以关注到句子中的关键信息,前馈神经网络使得模型可以处理长序列的文本。
算力无疑是这一轮 AI 爆点的关键因素。大模型参数动辄几十亿、成百上千亿,这对显卡的需求大幅提升。虽然已经有数据并行、模型并行、流水线并行等多卡训练的方式来解决训练速度慢、模型过大无法加载在单 GPU 上的问题, 但大模型消耗的大量算力仍然限制了其发展速度。比如最近 Meta 开源的 LLaMa3,训练过程耗费 770k GPU Hour,大模型的研发逐渐脱离了普通玩家,一定程度上演变成了算力竞赛。
考虑到大模型高昂的成本和落地可行性,目前的风向标飘向了垂直领域的小模型,各种对大模型减量不减质的方案方案如雨后春笋般出现,如知识蒸馏、模型压缩、模型剪枝等。这些方式保证了小模型在关键子空间的表达质量,大幅提升模型落地可行性。
神经网络算法目前的发展平缓,很难一夜研制出一套颠覆性的算法,小模型的商业模式又缓解了算力短缺的问题,这就使得高质量的数据成为了此轮模型战的决定因素。
数据生产
自从 LLaMa 开源后,很多小公司不再选择高成本的从头训练大模型的方案,而是选择在一个基础模型上进行训练,可以细化为两个训练过程:
- 预训练:使用无监督的方式对基础模型进行训练,使用的是未经标注的数据。
- SFT:使用监督方式对预训练的模型进行微调,使用的是已标注的指令数据。
合成数据
预训练的数据通常来自于某一领域的非结构化数据,经过清洗后喂给基础模型,此类数据通常来自于网络爬虫、客户知识库等。而 SFT 所需的数据是需要经过标注的,通常是人工标注的数据。考虑到人工标注的成本与效率,合成数据得到了广泛的应用。
合成数据是运用计算机等手段模拟生成的人造数据,它不包含真实数据,但从统计角度上反映了真实数据。使用合成数据进行 SFT 存在如下好处:
- 可以短期内产生大量数据、可以进行自动标注,减少人工成本。
- 合成数据避免了真实数据中涉及用户隐私的问题。
- 很容易地制造出现实中小概率出现的 corner data。
SFT 数据
SFT 通常采用标注的数据进行监督训练,这类数据被称为指令数据。指令数据本质上是一个问答对,但根据问题的具体程度,将指令分为以下三部分:
- Instruction:描述具体任务的指令,如“请根据给定内容提炼摘要”。
- Input:作为指令的补充,如上例中的给定内容。如果指令中的任务已明确,则其应为空。
- Output:任务的解答。
数据生产方案
对于 SFT 这种标注数据,通常借助 LLM 进行批量生成,下面详细介绍数据生产方案。
Self-Instruct
使用 LLM 生成指令数据的最早的方案是 SELF-INSTRUCT,该方案使用 GPT3 生成了大量指令数据并对 GPT3 进行了微调,指令生成流程如下:
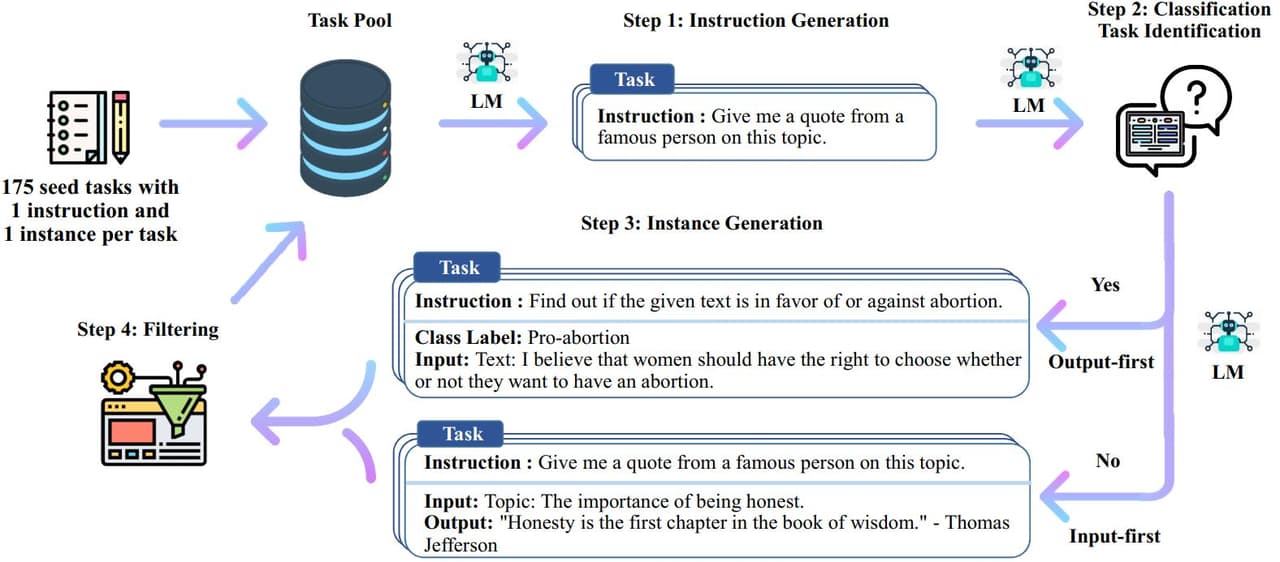
- 使用 175 个人工标注的指令数据作为种子数据放入任务池。
- 随机选择种子数据,并结合指令生成的 Prompt,使用 LLM 批量生成指令。
- 对生成指令进行划分,分为分类指令与生成式指令。
- 借助 LLM 生成 Input 与 Output,分类指令采用 Output-first方法,生成式指令采用 Input-first方法。
- 对生成的指令进行过滤,如问答长度过滤、RoughL 关联性过滤、黑词过滤等,并将过滤后的指令放入到任务池中进行迭代。
Self-Instruct 使用一个通用的 prompt 与种子数据,通过 GPT3 生成新的指令,进而生成相关的输入输出。种子数据用作示例,可以便于 LLM 返回标准的解析格式并以续写模拟的方式完成新指令的生成。
每次随机从种子数据中筛选出几个示例,这种随机性使得生成的指令具有丰富的多样性。
论文中给出了生产的数据质量,通过这些高质量的数据对 GPT3 进行微调,评测效果提升了33.1%。
Alpaca
Stanford 在此基础上进行了进一步扩展,使用 GPT3.5 生产出 52k 条数据并对开源的 LLaMa 模型进行微调,训练出 Alpaca 模型,这也是利用大模型训练小模型的经典之作。
Alpaca 在指令生成上沿袭了 Self-Instruct 的套路,但对此方法进行了简化:
- 指令不再区分分类指令与生成式指令。
- 使用 GPT3.5 一次性生成指令、输入与输出,避免指令和输入输出的两阶段生成。
借助于更强大的 LLM,Alpaca 简化的方法生成的策略仍然具备丰富的多样性,仅通过几百美元的成本快速训练出一个性能大幅提升的语言模型。
Chinese-LLaMA-Alpaca
Chinese-LLaMA-Alpaca 将 Alpaca 的数据生产应用到中文领域,借助 GPT3.5 生成中文指令去微调 LLaMa。
该项目进一步简化的指令生产的流程,相对于 Alpaca 移除掉了种子数据,使用更通用的 prompt 生成多样性的中文指令数据。
ALPAGASUS
AlpaGasus 在 Alpaca 指令集基础上,借助 LLM 进行了进一步过滤,将低质量的指令数据过滤掉。
其主要的思路是将 Alpaca 生成的指令逐条送给 ChatGPT 进行评分,选择评分高的一小批数据对 LLaMa 进行微调。
使用 LLM 评分过滤的方式将 52k 指令集过滤到 9k,微调后的性能有显著的提升。
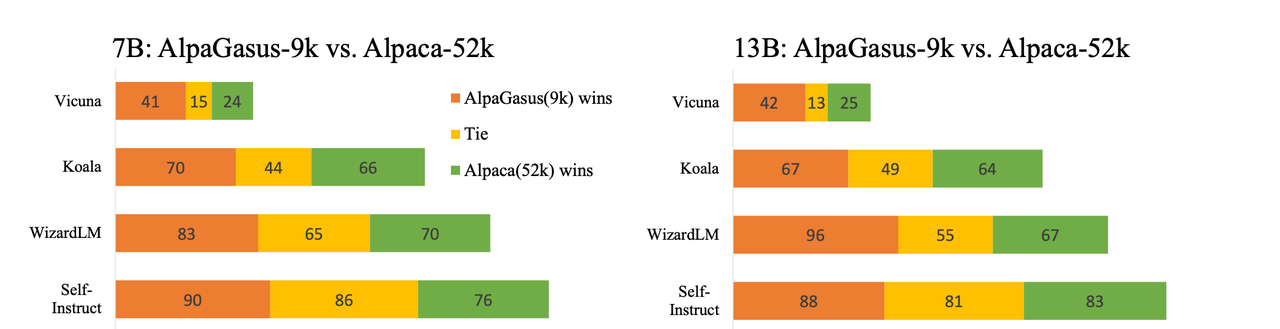
除了性能的提升,训练的成本也降低了很多,节省了大量训练时间。这表明数据质量对于 SFT 影响巨大,而数据数量反而对模型性能的影响有限。
与 AlpaGasus 类似,EasyInstruct 引入了插件式的指令清洗组件,将数据生产与数据清洗流程打通。
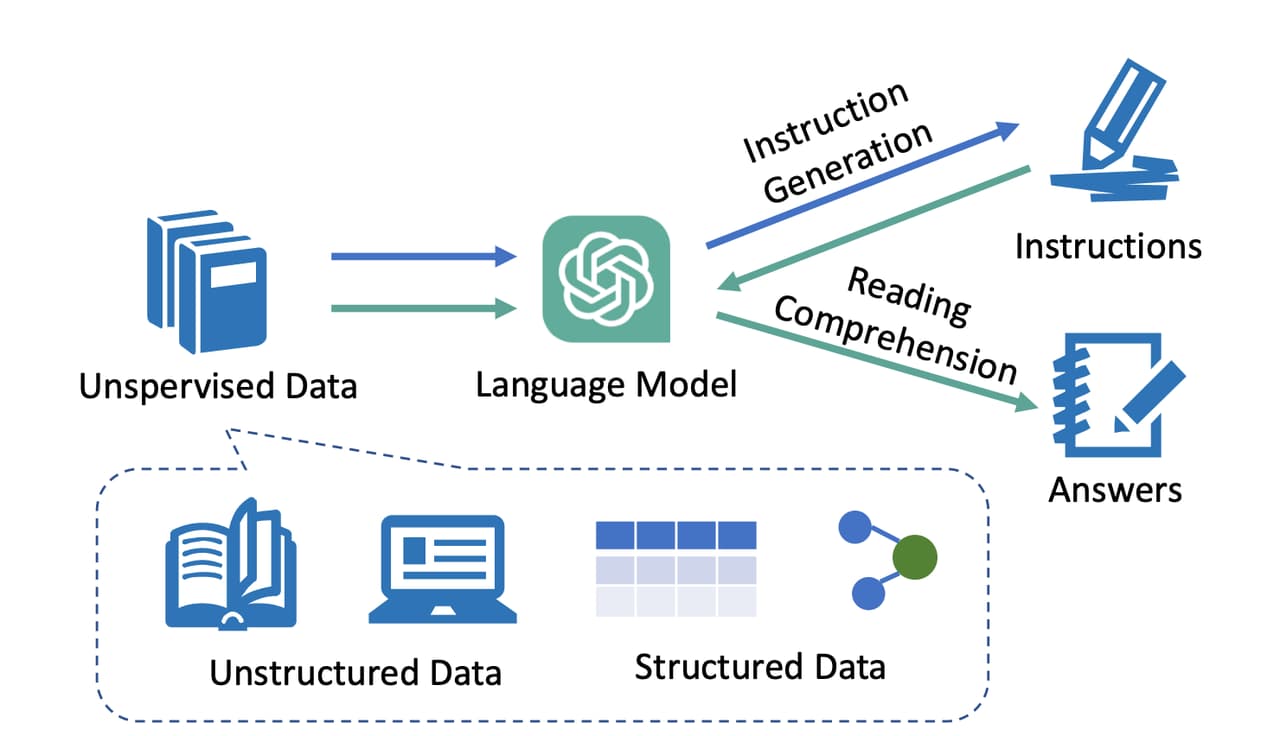
Self-QA
Self-QA 使用无监督的方式代替手工编写的种子指令,将非结构化的数据喂给 LLM,并让其根据此数据上下文生成指令数据。

总结
大模型对数据数量和质量提出了进一步要求,合成数据以其低成本、高灵活性在模型微调中扮演了重要的角色。 本文讨论了借助 LLM 进行数据生产的方案,顺着这个思路我们看到 LLM 在智能化、自动化方向上的有着广泛的应用,甚至在某些环节中可以做到自我完善。
从策略演进的过程我们看到,数据生产一方面依赖于大模型本身能力的提升,另一方面源于对 Prompt 工程的探索。